Oznámení
před 6 lety

- besanek
- Člen | 128
Také jsem dnes narazil na problém. Konkrétně s instalací přes
packagist. Pokud nainstaluji vývojovou verzi Nette a k němu přidám Lean
Mapper, tak laděnka mě hned seřve za stejně pojmenované třídy.
Ambiguous class Notes resolution; defined in
*libs/nette/nette/tests/Nette/bootstrap.php and in
*libs/tharos/leanmapper/tests/lib.inc.php.
Opravdu je nutné dávat do stabilních verzí testy? Popř. nešlo by je
zahrnout pod namespace?
S Composerem teprve začínám, takže snad neplácám nesmysly. :)
před 6 lety

- Tharos
- Člen | 1042
Šaman napsal(a):
Našel jsem jednu nevychytávku. Pokud nastavím některé property nějakou třídu, tak mi z databáze musí přijít instance stejné třídy (neprojde potomek).
Já se podobné vychytávky nezdráhám označit za logické bugy. :) Opraveno v develop větvi. Jak se to chová nyní je vidět v testech.
Samozřejmě pokud entita vyžaduje DateTime,
DibiDateTime jí musí uspokojit. DibiDateTime
je DateTime.
před 6 lety
- Tharos
- Člen | 1042
@besanek: Tu třídu v testech vůbec nepoužívám, a tak jsem ji beztak dal pryč. Nicméně…
Ty vše projíždíš Robot Loaderem, viď. ;) To je nejen zbytečné, ale
i nežádoucí. Ona Ti pak totiž aplikace stejně spadne – třeba na
entitě Author nebo Book, které jsou v testech také
nadefinované několikrát…
Pokud používáš Composer, jednoduše uprav nastavení Robot Loaderu tak, aby složku s knihovnami neprocházel (a aby procházel jen Tvůj aplikační kód). Stačí odstranit tenhle řádek. Composer se Ti o vše postará – uvidíš, že se vše potřebné nahraje a nenarazíš na žádný problém s duplicitami.
To, aby byly testy přítomny v repositáři a tím pádem i na Packagistovi, považuji za žádoucí.
před 6 lety
- besanek
- Člen | 128
Že mě to nenapadlo! Díky moc :)
K těm testům. Nette je v repozitáři také má a u stabilních 2.0.* se neinstalují. Nebo mi něco uniká?
Když se tak na dívám do nette repozitáře, tak mám dojem, že je za to odpovědný .gitattributes,:)
před 6 lety
- Tharos
- Člen | 1042
Tak tohle jsem vůbec neznal, díky za tip :). Rád tohohle využiji.
před 6 lety

- castamir
- Člen | 631
Tharos: už mám po státnicích, takže se ti na to zítra pořádně mrknu a zkusím ti k tomu tvému výtvoru udělat recenzi :p
před 6 lety
- castamir
- Člen | 631
postupně pročítám featury a dostal jsem se k implementaci enum. Když
už děláš enum, měl bys IMHO přidat i set. Používá se sice
ještě méně častěji jak enum, ale pro některé případy se fakt hodí
(checkbox-listy).
před 6 lety
- Tharos
- Člen | 1042
Lean Mapper si přes víkend pomohl k pár užitečným funkcím. Prozatím jsou k vidění v brenši sqlStrategy (do develop větve to mergnu až s testy nových funkcí) a já se tu teď pokusím co možná nejlépe vysvětlit, co ten záhadný název vlastně znamená. :)
Mikrodokumentace k filtrům
To, čemu v Lean Mapperu říkám filtry (a co se dá zapsat pomocí
m:filter() příznaku v anotacích), je úplně triviální
koncept. Jedná se o způsob, jak doladit připravený DibiFluent
dotaz těsně před tím, než se přeloží do SQL a spustí nad databází.
Nic víc, nic míň. Pokud například máte entitu Author a
načítáte knihy Book, které autor napsal
($author->books), Lean Mapper připraví potřebný
DibiFluent statement, ale ještě před tím, než jej přeloží
do SQL a pošle databázi, dovolí vám do něj sáhnout a cokoliv v něm
upravit.
Důvodů pro takové „sáhnutí“ může být neskutečně mnoho: můžeme chtít výsledek limitovat, řadit, přijoinovat nějakou tabulku (například u entit rozlezlých přes více tabulek nebo u nějakých překladů )… Dá se s tím dělat skutečně hodně a fantazii se meze nekladou.
Blížím se k jádru věci a aby výklad nebyl tak abstraktní, přistoupím rovnou k příkladům. :) Schéma databáze odpovídá této.
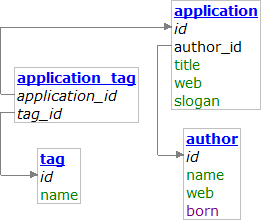{kind=link}
Zadání: vypište všechny autory a ke každému vypište jednu aplikaci, jejímž je autorem.
class CommonFilter
{
public static function limit(DibiFluent $statement, $limit = null)
{
if ($limit !== null) {
$statement->limit($limit);
}
}
}
/**
* @property int $id
* @property string $name
* @property string $web
* @property Application[] $applications m:belongsToMany(#union) m:filter(CommonFilter::limit)
* @property DateTime|null $born
*/
class Author extends LeanMapper\Entity
{
}
/**
* @property int $id
* @property DateTime|null $released
* @property Author $author m:hasOne
* @property string $title
* @property string|null $web
* @property string $slogan
*/
class Application extends LeanMapper\Entity
{
}
class AuthorRepository extends LeanMapper\Repository
{
public function findAll()
{
return $this->createEntities(
$this->connection->select('*')->from($this->getTable())->fetchAll()
);
}
}Domyslete si jmenné prostory, use statementy a tak podobně… Vypsat to, co je požadováno v zadání, je poté velmi triviální:
$authorRepository = new AuthorRepository($connection);
foreach ($authorRepository->findAll() as $author) {
echo $author->name . "\n";
foreach ($author->getApplications(1) as $application) {
echo $application->title . "\n";
}
echo "-----\n";
}Osvětleme si následující definici:
@property Application[] $applications m:belongsToMany(#union) m:filter(CommonFilter::limit)Díky ní jsme schopni pro každého autora získat aplikace, jejichž je autorem.
Lean Mapper připraví dotaz (přesněji DibiFluent), který
těsně před přeložením do SQL ještě prožene přes metodu
CommonFilter::limit. Té předá jako parametr zmíněnou instanci
DibiFluent a pak všechny parametry, které byly předány při
volání $author->getApplications(...) (přistupujeme
k položce voláním „virtuální“ metody právě proto, abychom byli
schopni předat parametry, jinak by samozřejmě stačilo
$author->applications).
Co ale znamená ono záhadné #union? A proč se větev v Gitu
jmenuje tak, jak se jmenuje? :)
Lean Mapper sestavuje dotazy „v duchu NotORM“, a proto v našem
příkladu načítá související aplikace i pro ostatní autory, které jsme
získaly při volání $authorRepository->fetchAll(). Podle
výchozí strategie tedy připraví následující dotaz (vyobrazená
ID samozřejmě závisí na konkrétních datech v databázi):
SELECT `application`.* FROM `application` WHERE `application`.`author_id` IN (11, 12)Pokud do tohoto dotazu ale filtr přidá na konec LIMIT 1,
dostaneme jiný výsledek, než jaký jsme původně zamýšleli. My přece
nechceme limitovat výsledek s aplikacemi pro všechny autory. To, co my
potřebujeme (a je to velmi hezky popsáno v tomto článku), je, aby se Lean Mapper zeptal
následovně:
(SELECT `application`.* FROM `application` WHERE `application`.`author_id` = 11 LIMIT 1)
UNION (SELECT `application`.* FROM `application` WHERE `application`.`author_id` = 12 LIMIT 1)A přesně k tomu slouží onen obrat #union. U vazeb
m:hasMany, m:belongsToMany a
m:belongsToOne lze definici zakončit tímto dovětkem /validní je
tedy například i m:belongsToMany(maintainer_id#union),
m:belongsToMany(maintainer_id:application#union) a tak podobně / a Lean Mapperu tím říkáme, že má pro
získání potřebných dat použít „UNION strategii“. Důležité té, že
Lean Mapper pak aplikuje filtr(y) na každou samostatnou část té
UNION sekvence (všimněte si dotazů výše – LIMIT se nachází
u každé části). A pak už je výsledek podle našeho očekávání.
Možná to zní divoce, ale princip je skutečně jednoduchý. Pokud
pracujeme s filtry, ladíme SQL dotazy, které se následně položí
databázi. Je nutné počítat s tím, že Lean Mapper klade konstantní počet
dotazů a jím generované dotazy podle toho vypadají. Takovéto dotazy lze ale
občas obtížně limitovat a řadit, a proto lze Lean Mapperu říct, aby ten
či onen dotaz připravil podle jiné strategie (tj. aby použil
UNION namísto IN) – to proto, aby jej bylo možné
limitovat a řadit.
K některým úkonům tato alternativní strategie není vůbec zapotřebí (například při-joinování nějaké tabulky s překlady atp.), k některým úkonům je víceméně nutná (limitování a řazení).
Editoval Tharos (17. 6. 2013 0:24)
před 6 lety
- Tharos
- Člen | 1042
Dovolím si ještě takový malý dovětek pro ty, které jsem vyděsil… Získávání dat přes UNION je podle mě zapotřebí jen opravdu zřídka.
Typicky je zapotřebí limitovat hlavní výsledek získaný přímo z repositáře a v takovém případě lze samozřejmě výsledek limitovat bez jakýchkoliv komplikací přímo v repositáři:
class AuthorRepository extends LeanMapper\Repository
{
public function findAll($offset = null, $limit = null)
{
return $this->createEntities(
$this->connection->select('*')->from($this->getTable())
->fetchAll($offset, $limit)
);
}
}Pro ty, které jsem nevyděsil, si ale dovolím připojit ještě jednu ukázku. :)
Zadání: Načtěte všechny aplikace a ke každé vypište jeden tag, kterým je označena. Název tohoto tagu vypište velkými písmeny, přičemž konverzi velikosti písmen proveďte na úrovni databáze.
Potřebujeme k tomu následující:
class CommonFilter
{
public static function limit(DibiFluent $statement, $limit = null)
{
if ($limit !== null) {
$statement->limit($limit);
}
}
}
class TagFilter
{
public static function upper(DibiFluent $statement)
{
$statement->select('UPPER([name]) [name]');
}
}
/**
* @property int $id
* @property DateTime|null $released
* @property Author $author m:hasOne
* @property Tag[] $tags m:hasMany(#union) m:filter(CommonFilter::limit|TagFilter::upper)
* @property string $title
* @property string|null $web
* @property string $slogan
*/
class Application extends LeanMapper\Entity
{
}
/**
* @property int $id
* @property string $name
*/
class Tag extends LeanMapper\Entity
{
}
class ApplicationRepository extends LeanMapper\Repository
{
public function findAll()
{
return $this->createEntities(
$this->connection->select('*')->from($this->getTable())->fetchAll()
);
}
}Vybaveni tímto kódem můžeme provést následující:
$applicationRepository = new ApplicationRepository($connection);
foreach ($applicationRepository->findAll() as $application) {
echo $application->title . "\n";
foreach ($application->getTags(1) as $tag) {
echo $tag->name . "\n";
}
echo "-----\n";
}Osvětleme si tentokrát následující anotaci v entitě
Application:
@property Tag[] $tags m:hasMany(#union) m:filter(CommonFilter::limit|TagFilter::upper)Pomocí jí opět získáme možnost přistupovat z aplikace k tagům,
kterými je označena (vztah M:N). Důležité je uvědomit si, že k tagům se
musíme vydat přes spojovací tabulku (v našem případě
application_tag – její název neuvádíme, protože dodržuje
konvence). Protože budeme chtít doladit dotaz směřující do spojovací
tabulky (kvůli limitu) a i dotaz směřující do cílové tabulky s tagy
(kvůli převodu názvu na velká písmena), filtr má dvě části. První
část se použije při dotazování se do spojovací tabulky, druhá část se
použije při dotazování do tabulky s tagy.
Aby nám limit fungoval podle očekávání, musíme použít UNION strategii.
Dodatek:
Za zmínku také stojí, že každá část filtru může obsahovat více callbacků (oddělují se čárkami). Následující zápis filtru je validní:
m:filter(CommonFilter::limit,OrderFilter::order|TagFilter::upper)Pokud potřebujete takto složité filtry, můžete narazit na problém s parametry (každému callbacku byste potřebovali předat něco jiného). Nejsnazší řešení je zavedení jednoduchého query objektu (což může být klidně jen i pole s dohodnutými klíči), který při přístupu k položce použijete a ze kterého si každý callback vytáhne to, co potřebuje.
$books = $author->getBooks(array(
'limit' => 4,
'offset' => 2,
'search' => 'MySQL',
'order' => 'title',
));Dolazování dotazů (filtry) je asi nejsložitější koncept v celém Lean Mapperu. Pointa je ale jednoduchá a myslím, že se vyplatí do tohoto aspektu ORM proniknout, protože to umožňuje stručně vyřešit i velmi spletité záležitosti.
Editoval Tharos (17. 6. 2013 0:35)
před 6 lety
- Tharos
- Člen | 1042
@castamir: Díky za zajímavý tip. Poprosil bych o navedení, jak by to mělo fungovat (myslím ze strany API) a také o nějaký use-case (třeba kdybys lehce rozvedl ty checkboxy). Přiznám se, že zatím si teprve ujasňuji, co si pod tím mám představit. :)
před 6 lety

- David Ďurika
- Člen | 341
@Tharos neslo by do constructu entity vkladat aj pole ?
v baseEntite som si spravil nieco taketo:
<?php
public function __construct($data = null)
{
$row = NULL;
if($data instanceof Row) {
$row = $data;
}
parent::__construct($row);
if(is_array($data)) {
$this->assign($data);
}
}
?>ale bolo by fajn keby to bolo uz v \LeanMapper\Entity
před 6 lety
- castamir
- Člen | 631
@Tharos
Typické použití je v nastavování skupinových vlastností uživatele
v profilu/administraci. V administraci to může být např.
nastavení práv…
Jen pro upřesnění – set (=množina) je vlastně enum (má omezený výčet hodnot), ale liší se tím, že set může mít víc hodnot nastavených zaráz (při právech {quest, user, vip, admin} může konkrétní hodnota uživatele mít podobu např. „user,vip“).
Z hlediska definice property by to mělo být v podstatě stejné jako u enum tzv. něco jako m:set. Co se týče defaultní implementace, tak já dávám ten celkový výčet do pole tak, že konkrétní hodnoty z množiny jsou klíče a hodnotou jednotlivých položek pole jsou true/false podle toho, zda je konkrétní hodnota z množiny nastavena nebo ne:
$rights = array(
"guest" => FALSE,
"user" => TRUE,
"vip" => TRUE,
"admin" => FALSE
);klíče s nastavenou hodnotou true lze získat velice snadno
$user_rights = array_keys($rights, TRUE);
$comma_separated = implode(",", $user_rights);nastavení hodnot je právě díky doplňkům typu checkboxlist nebo nette-forms-inputlist
vlastně jen přiřazení hodnot. Pokud bych to chtěl nějak explicitně
ošetřit, tak funkcí
array_intersect_key($nova_prava, $vsechna_prava).
Editoval castamir (17. 6. 2013 10:42)
před 6 lety
- Tharos
- Člen | 1042
Mimochodem… Poctivě aktualizuji tuhle stránku, ze které je patrné, jaké změny se v Lean Mapperu odehrály/odehrají od verze 1.3.1.
Všimněte si, že naprostá většina featur do verze 1.4 už je hotová. Vydám ji velmi brzy.
Poté bude následovat stop stav pro přidávání nových featur a zaměřím se zase na dokumentaci, kterou bych chtěl významně rozšířit (přibude dokumentace pro filtry, veškeré nové funkce, low-level záležitosti a také připravím ty ukázky pokročilejšího využití, které se teď válejí tady na fóru).
před 6 lety
- castamir
- Člen | 631
@Tharos ještě mám jeden prekérní dotaz (ptám se na tuto otázku všech autorů všech ORMek :D).
Půjde (a popř. jak) nějak zařídit, abych mohl tahat data implicitně jako join 2 tabulek? Všiml jsem si, že nemáš explicitně žádný mapper, kde bych to dal tak nějak z první, ale tady je maximálně repository (dao). Příklad: mám hierarchicky strukturovaná data uložená v db např. pomocí closure table (tabulky category a category_closure), takže bych očekával, že budu moct klasicky pracovat jen s category, ale pokud bych chtěl strukturovaná data (představit si to můžeš jako víceúrovňové menu), pak bych chtěl získávat data na základě selectu, který automaticky přidá join (nebo i více joinů) do category_closure.
Jak na to? Dva repository (např strukturovaný podědí od klasického pro category)?
EDIT: jde tu ještě o speciální zacházení při ukládání či mazání prvků – je nutné přidávat resp. patřičně upravovat i tabulku category_closure kdykoliv se přidá nebo smaže nějaký prvek v tabulce category…
Editoval castamir (17. 6. 2013 10:55)
před 6 lety
- Tharos
- Člen | 1042
@castamir: Už jsem se tohohle Tvého křtu ohněm nemohl dočkat :D. Snad Tě potěší, že tohle má v Lean Mapperu vcelku triviální řešení :D.
Předvedu Ti teď čtení (které rozhodně považuji za zajímavější) a persistenci doplním někdy večer…
V ukázce budu pracovat přesně s touto databází. Mějme následující třídy:
/**
* @property int $id
* @property string $name
*/
class Category extends LeanMapper\Entity
{
const DIRECTION_ANCESTOR = 'ancestor';
const DIRECTION_DESCENDANT = 'descendant';
public function getDescendants()
{
return $this->getCategoriesInTree(self::DIRECTION_DESCENDANT);
}
public function getAncestors()
{
return $this->getCategoriesInTree(self::DIRECTION_ANCESTOR);
}
private function getCategoriesInTree($direction)
{
$categories = array();
$rows = $this->row->referencing('category_closure', null, $direction === self::DIRECTION_DESCENDANT ? self::DIRECTION_ANCESTOR : self::DIRECTION_DESCENDANT);
foreach ($rows as $row) {
$categoryRow = $row->referenced('category', null, $direction);
$categoryRow->depth = $row->depth;
$categories[] = new CategoryInTree($categoryRow);
}
return $categories;
}
}
/**
* @property-read int $depth
*/
class CategoryInTree extends Category
{
}
class CategoryRepository extends LeanMapper\Repository
{
public function find($id)
{
// přímočará implementace, neřešme teď neexistující ID...
return $this->createEntity(
$this->connection->select('*')->from($this->getTable())->where('id = %i', $id)->fetch()
);
}
public function findAll()
{
return $this->createEntities(
$this->connection->select('*')->from($this->getTable())->fetchAll()
);
}
}No a to je ve zkratce vše, co pro čtení potřebuješ. :)
Situace 1 z odkazovaného článku má pak takovéto řešení:
$category = $categoryRepository->find(2);
foreach ($category->descendants as $descendant) {
echo "$descendant->name ($descendant->depth)" . "\n";
}Výstup je následující:
Tiskárny (0)
Laserové (1)
Inkoustové (1)Databázi se položí následující dotazy:
SELECT * FROM `category` WHERE id = 2 LIMIT 1
SELECT `category_closure`.* FROM `category_closure` WHERE `category_closure`.`ancestor` IN (2)
SELECT `category`.* , null `depth` FROM `category` WHERE `category`.`id` IN (2, 3, 4)Situaci 2 z odkazovaného článku pak lze řešit následovně:
$category = $categoryRepository->find(4);
foreach ($category->ancestors as $ancestor) {
echo "$ancestor->name ($ancestor->depth)" . "\n";
}Výstup je následující:
PC příslušenství (2)
Tiskárny (1)
Inkoustové (0)Databázi se položí následující dotazy:
SELECT * FROM `category` WHERE id = 4 LIMIT 1
SELECT `category_closure`.* FROM `category_closure` WHERE `category_closure`.`descendant` IN (4)
SELECT `category`.* , null `depth` FROM `category` WHERE `category`.`id` IN (1, 2, 4)Dovolím si ještě jednu zajímavou ukázku. :) Proveďme následující:
$categories = $categoryRepository->findAll();
foreach ($categories as $category) {
echo $category->name . "\n";
foreach ($category->descendants as $descendant) {
echo " - $descendant->name ($descendant->depth)\n";
}
}Dostaneme takovýto výstup:
PC příslušenství
- PC příslušenství (0)
- Tiskárny (1)
- Laserové (2)
- Inkoustové (2)
- Myši (1)
- Optické (2)
- Laserové (2)
- Klávesnice (1)
- Drátové (2)
- Bezdrátové (2)
Tiskárny
- Tiskárny (0)
- Laserové (1)
- Inkoustové (1)
Laserové
- Laserové (0)
Inkoustové
- Inkoustové (0)
Myši
- Myši (0)
- Optické (1)
- Laserové (1)
Optické
- Optické (0)
Laserové
- Laserové (0)
Klávesnice
- Klávesnice (0)
- Drátové (1)
- Bezdrátové (1)
Drátové
- Drátové (0)
Bezdrátové
- Bezdrátové (0)A proč tom píšu? Protože stojí za povšimnutí, jak hezky a úsporně se Lean Mapper zeptá do databáze:
SELECT * FROM `category`
SELECT `category_closure`.* FROM `category_closure` WHERE `category_closure`.`ancestor` IN (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
SELECT `category`.* , null `depth` FROM `category` WHERE `category`.`id` IN (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)Prostě i v takovémto spletitém případě je díky využití „NotORM principu“ počet dotazů konstantní a nikam „neustřelí“.
Tak co, obstálo ORMko nebo ne? :)
Editoval Tharos (17. 6. 2013 17:57)
před 6 lety
- castamir
- Člen | 631
@Tharos: nice, nice, NICE! :D
1:0 pro Lean Mapper :D
teď ještě ukládání a mazání, ale tentokrát neber inspiraci z blogu Honzy Voráčka, ale z mého, neboť v tom mém opravuju některé „díry“, které tam Honza má. Každopádně i přesto je ten Honzův blogpost super základ na demonstraci řešení tohoto problému.
před 6 lety
- Tharos
- Člen | 1042
Super, vyjdu tedy z Tvého článku. :)
Persistenci doplním, jen prosím o chvilku strpení… Potřebuji teď zase trochu posunout své komerční projekty. :)
před 6 lety
- castamir
- Člen | 631
@Tharos v nejbližších dnech (resp. jakmile dodělám grafiku), tak to hned vyzkouším na jednom novém rozsáhlejším projektu. Do dvou týdnů ostrého testování budu vědět víc.
před 6 lety
- Tharos
- Člen | 1042
Super. Kdybys potřeboval podporu (třeba jen nástřel, jak bych co řešil já), dej vědět. Early adoptery si hýčkám ;). Možnost poznat styl myšlení a požadavky ostatních vývojářů má pro mě při vývoji knihovny obrovskou cenu.
před 6 lety
- besanek
- Člen | 128
Taky nasazuji na ostrou aplikaci, byť to nebude nic velkého.
Ale napadl mě pekelný nápad. Když je vytvoření stromové struktury v Lean Mapperu tak snadné, jestli by nestálo za to zvážit ho tam dát od základu.
Bohužel mě teď nenapadá, jak to efektivně zapsat pomocí anotací. Možná by tohle ani ORM řešit nemělo.
před 6 lety
- castamir
- Člen | 631
@besanek tohle tam IMHO nemá co dělat. Closure table je jedna z většího množství metod, která umožňuje pracovat s hierarchicky strukturovanými daty. Pokud bys chtěl jinou, musel bys udělat další rozšíření a pak další a další a z malého kompaktního ORM by se stal robustný strašák.
Řešit bys to musel stejně nejspíš pouze pomocí trait (sdílená implementace), což je polovičaté řešení, neboť traity fungují až od PHP 5.4…
před 6 lety
- besanek
- Člen | 128
To mi bylo jasné už v době psaní mého příspěvku. Traity mě napadli taky a asi si to pomocí nich udělám.
před 6 lety

- tomas.lang
- Člen | 54
Předem děkuji autorovi za práci na této moc pěkné knihovně – jde vidět že autor má koncepci pevně v rukou a dobre ví co chce… :-)
Každopádně pro píši – pustil jsem se do letmé implementace ve starším projektu a narazil jsem na problém – obecně jsem dost využíval fluent syntaxe např. na pohodlné pozdější přidávání ORDER klauzule – chtěl bych se tedy zeptat jak by autor elegantně řešil problém s řazením nad repozitáři. Moc nechce do budouvání x metod pro jednotlivá řazení, ale co se týče metody findAll, zde již zase nemám šanci do budovaného query moc zasáhnout.
Osobně se mi líbí myšlenka filtrů, ale jestli dobře chápu, ty jsou definovány pouze nad entitami – je zamýšlená obdobná možnost i pro repositáře?
před 6 lety

- Šaman
- Člen | 2275
Tharos napsal(a):
Šaman napsal(a):
Tak jsem na to narazil znovu, tentokrát z druhé strany. Metodě assign() nejde předat ArrayObject, ani ArrayHash, protože striktně vyžaduje pole. Možná by bylo lepší používat méně striktní rozhraní ArrayAccess, IteratorAggregate a Countable.Jo, tohle by mohlo být fajn. :) Souhlasím, že instancí, která implementuje zmíněná rozhraní, by to pohrdat nemuselo. :) Tohle pravděpodobně naimplementuji. Edit: I když ještě to zvážím, ono zde lze zase použít
iterator_to_array($values)…
Tohle zas tak moc nebolí, ale bylo by fajn, kdybych nemusel přetypovávat při každém přiřazení, ale pokud by tato metoda nedostala pole, ale bylo by splněné rozhraní, tak by si sama přetypovala ‚$values = (array) $values‘
Tharos napsal(a):
Šaman napsal(a):
Bylo by super, kdyby bylo místo entit možné předávat jen jejichid. Opět typicky při práci s formuláři.<?php $authorId = $form->values->author; # $authorId = 5 $book->author = $authorId; # InvalidValueException: Only entites can be set via magic __set on field with relationships. $book->author = $this->authorRepo->get($authorId); # projde, ale přijde mi to zbytečně ukecané, navíc potřebuji repozitář ?>Tohle mi přijde mírně na hraně a myslím, že by podpora pro podobné prakticky neměl být přímo v jádru Lean Mapperu. Prostě přiřazovat
$book->author = $authorIdje WTF a proti principům objektové strany ORM. A to já jsem dost benevolentní ;).Každopádně, tohle má velmi jednoduché řešení. Opět si stačí vytvořit
BaseEntity(je zapotřebí aktuální verze z develop větve) a v ní mít:class BaseEntity extends LeanMapper\Entity { public function setById($field, $id) // this is only draft, it doesn't handle exceptional states! { $property = $this->getReflection()->getEntityProperty($field); $relationship = $property->getRelationship(); $this->row->{$property->getColumn() . '_id'} = $id; $this->row->cleanReferencedRowsCache($relationship->getTargetTable(), $relationship->getColumnReferencingTargetTable()); } }Pak budeš moci provést následující:
$bookRepository = new BookRepository($connection); $book = $bookRepository->find(1); echo $book->author->name; // prints some name $book->setById('author', 2); echo $book->author->name; // prints another nameJsem si jist, že kdybys tohohle chtěl masivně využívat, půjde to zařídit v
BaseEntitytak, abys s tím měl v konkrétních entitách už minimum psaní.
Abych pravdu řekl, chtěl bych to masivně používat, je to totiž
nejjednodušší způsob vytváření entit z formulářů. Řekněmež, že
entita Book má vazbu na Author v property
$author.
Teď je jediná varianta
<?php
// máme $authorId, ať už z formuláře, nebo odkudkoliv
$author = $authorRepository->get($authorId);
$book->author = $author;
?>Ale ve formuláři na vytvoření knihy pak musím mít injectované všechny repository, na jejichž entity má kniha vazbu (přitom ty sám vazbu mezi repozitáři nepoužíváš). Navíc je to neefektivní, protože v tomto případě chci skutečně jen nastavit idčka do databáze.
Jako variantu bych viděl buď mít možnost nastavit nějakou virtuální
property $authorId (nebo $author_id), nebo předat
místo entity její id.
Tvoje řešení zkouším, ale nechci si vytvářet nové settery na
předání idčka. Rád bych, aby to fungovalo i na assign a
new Book(). Takže jsem došel k tomuhle:
<?php
/**
* Umožňuje předat entitě místo navázaných entit jejich 'id'
*
* @param string $name
* @param mixed $value
*/
function __set($name, $value)
{
$property = $this->getReflection()->getEntityProperty($name);
if ($property->hasRelationship() && !($value instanceof Entity) && is_int($value))
{
$relationship = $property->getRelationship();
$this->row->{$property->getColumn() . '_id'} = $value;
$this->row->cleanReferencedRowsCache($relationship->getTargetTable(), $relationship->getColumnReferencingTargetTable());
}
else
{
parent::__set($name, $value);
}
}
?>Vidíš v tom nějaký háček? Zatím to řeší jen vazbu 1:m, rozšiřování tohoto hacku nechám na později, pokud bys to do té doby nechtěl nějak umožnit přímo v LM.
před 6 lety
- Tharos
- Člen | 1042
@tomas.lang: Filtry tak, jak je zde prezentuji, jsou
technicky vzato jednoduché utility třídy
se statickými funkcemi, které jen nějakým způsobem rozvíjejí připravený
DibiFluent.
Jednou připravený filtr lze použít kdekoliv. V entitě (a logicky u položek nadefinovaných pomocí anotace se filtr musí nějak nadefinovat v rámci té anotace), ale lze jej použít i v repositáři prostým zavoláním té požadované statické metody filtru.
Abych uvedl nějaký příklad, řekněme, že v aplikaci budu chtít limitovat a řadit. Pokud budu chtít limitovat a řadit jenom v jednom konkrétním repositáři, implementace může být velmi přímočará:
class ApplicationRepository extends LeanMapper\Repository
{
public function findAll($orderBy = null, $offset = null, $limit = null)
{
$statement = $this->connection->select('*')->from($this->getTable());
if ($orderBy !== null) {
$statement->orderBy($orderBy);
}
return $this->createEntities(
$statement->fetchAll($offset, $limit)
);
}
}Řekněme ale, že pak zjistíš, že chceš řadit a limitovat ještě
i někde jinde. Řešení je hned několik… Lze to vyřešit například
nějakým protected helperem v BaseRepository, anebo, a to je asi
nejkomplexnější, to lze vyčlenit do utility třídy. Tu pak lze
používat jako filtr.
Jak taková utility třídy může vypadat a jak ji lze použít i v repositáři:
class CommonFilter
{
public static function orderAndLimit(DibiFluent $statement, $orderBy = null, $offset = null, $limit = null)
{
if ($orderBy !== null) {
$statement->orderBy($orderBy);
}
if ($limit !== null) {
$statement->limit($limit);
}
if ($offset !== null) {
$statement->offset($offset);
}
}
}
class BookRepository extends LeanMapper\Repository
{
public function findAll($orderBy = null, $offset = null, $limit = null)
{
$statement = $this->connection->select('*')->from($this->getTable());
CommonFilter::orderAndLimit($statement, $orderBy, $offset, $limit);
return $this->createEntities(
$statement->fetchAll()
);
}
}Výhodou takhle vyčleněného kódu je, že jej lze snadno použít i u entit:
/**
* @property Book[] $books m:belongsToMany(#union) m:filter(CommonFilter::orderAndLimit)
*/
class Author extends LeanMapper\Entity
{
}
// zde by bylo nahrání $author z repositáře atp.
$author->getBooks('name', 5); // knihy budou seřazeny podle jména a bude vráceno pět prvníchPraktické je, že argumentem filtru nemusí být pouze skalární hodnoty:
class SearchFilter
{
public function applyQuery(DibiFluent $statement, array $query)
{
if (isset($query['title'])) {
$statement->where('[title] = %s', $query['title']);
}
if (isset($query['year'])) {
$statement->where('[year] = %y', $query['year']);
}
if (isset($query['limit'])) {
$statement->limit($query['limit']);
}
}
}
/**
* @property Book[] $books m:belongsToMany(#union) m:filter(SearchFilter::applyQuery)
*/
class Author extends LeanMapper\Entity
{
}
// zde by bylo nahrání $author z repositáře atp.
$author->getBooks(array(
'title' => 'Book about John Doe',
'year' => 2013,
)); // související knihy budou vyhledány podle uvedených kritériíTakový filtr by opět šel použít i v repositáři bez nutnosti opakovat
vlastní kód filtru… Doplním, že namísto array může být
použit i nějaký rozvitější query object.
Napadla mě i jedna úplně exotická varianta:
class CallbackFilter
{
public function apply(DibiFluent $statement, Closure $callback)
{
$callback($statement);
}
}
/**
* @property Book[] $books m:belongsToMany(#union) m:filter(CallbackFilter::apply)
*/
class Author extends LeanMapper\Entity
{
}
// zde by bylo nahrání $author z repositáře atp.
$title = 'Some book';
$author->getBooks(function (DibiFluent $statement) use ($title) {
$statement->where('[title] = %s', $title);
});Zkrátka celý mechanismus je extrémně pružný a z principu jen velmi málo omezený.
Doufám, že je pro Tebe má odpověď přínosná. Pokud ne, klidně vymysli nějaké konkrétní zadání. :)
před 6 lety
- Tharos
- Člen | 1042
@Šaman: Ideálně by taková BaseEntity
měla vypadat nějak takto:
class BaseEntity extends LeanMapper\Entity
{
public function __set($name, $value)
{
$property = $this->getCurrentReflection()->getEntityProperty($name);
if (
$property !== null and
$property->hasRelationship() and
($property->getRelationship() instanceof LeanMapper\Relationship\HasOne)
) {
$relationship = $property->getRelationship();
$this->row->{$relationship->getColumnReferencingTargetTable()} = $value;
$this->row->cleanReferencedRowsCache($relationship->getTargetTable(), $relationship->getColumnReferencingTargetTable());
} else {
parent::__set($name, $value);
}
}
}Takže skoro přesně tak, jak jsi ji napsal Ty. :) Háček v tom žádný není.
Edit: Odstraněna validace, že je $value integer
Edit2: Kód upraven pro kompatibilitu s chystanou verzí 1.5
Editoval Tharos (12. 8. 2013 22:03)
před 6 lety
- Tharos
- Člen | 1042
Šaman napsal(a):
Tohle zas tak moc nebolí, ale bylo by fajn, kdybych nemusel přetypovávat při každém přiřazení, ale pokud by tato metoda nedostala pole, ale bylo by splněné rozhraní, tak by si sama přetypovala ‚$values = (array) $values‘
Tak jsem podporu pro tohle nakonec přidal. Ukázka použití je zde.
Ve spojení s výše uvedenou BaseEntity by tedy mělo být
možné vytvářet entitu z dat z formuláře i včetně 1:N závislostí
následovně:
$book = new Book($form->getValues());
// $bookRepository->persist($book);
// echo $book->author->name; // vypíše název autoraCož je skoro návykové, já uvedenou BaseEntity asi taky budu
používat :).
Editoval Tharos (18. 6. 2013 6:53)
před 6 lety
- Šaman
- Člen | 2275
Díky!
Jediný, co jsem ještě změnil (i když už to je trochu hodně
benevolentní) je, že nekontroluji, zda předané $id je integer. Původně
jsem to tam dal taky, ale formulář mi bohužel vrací řetězec.
Jinak tímto potvrzuji funkčnost tohoto ORMu i v případě, že používám důsledně ArrayHash, kolekce entit a jednoduché přiřazování pomocí pole, které obsahuje místo vazeb idčka.
Mám to okořeněné špetkou magie a použití se již blíží přesně tomu, jak bych si jednoduchý ORM představoval:
BaseRepository navíc u mě umí dotazy jako
getByEmail($email), nebo
findByAuthorAndGenre($author, $genre), pokud jsou tyto metody
uvedeny v anotacích (což zajišťuje i našeptávání). Get mi vždy vrací
jedinou entitu, find vždy kolekci.
BaseCollection umí ->fetchPairs($col1, $col2) a asi ho
doučím ještě řazení a limity.
BaseEntity mi implementuje rozhraní IResource, takže napojení na ACL je velmi jednoduché.
před 6 lety

- Filip111
- Člen | 244
@Tharos:
Ahoj,
začal jsem trochu zkoušet práci s vícejazyčními entitami, jak jsi mi
před nějakou dobou naznačil a připravil mi ke stažení ukázku. Narazil
jsem na problém a dotaz:
1) problém – zmizela metoda
getModifiedData()
nová metoda getModifiedRowData() vrací sloupce již
přejmenované podle property (datetimeCreated) a nikoliv podle sloupce v DB
(date_created) – tedy nízkoúrovňovou metodu nahradila vysokoúrovňová,
ale k nízkoúrovňové není náhrada. Zrovna v tomhle případě je
potřebná.
Příklad v repository, který jsi uvedl pro persist pak nefunguje –
nezafunguje array_intersect_key, protože
getModifiedRowData vrátí místo klíče date_created
klíč dateCreated. Alternativu k původní metodě jsem
nenašel.
public function persist(Entity $entity) {
if ($entity->isModified()) {
//$values = $entity->getModifiedData();
$values = $entity->getModifiedRowData();
if ($entity->isDetached()) {
$this->connection->insert(
$this->getTable(),
array_intersect_key($values, array_flip(array('id', 'date_created', 'status')))
)->execute();
$id = $this->connection->getInsertId();
$this->connection->insert(
'page_translation',
array_intersect_key($values, array_flip(array('lang', 'text'))) + array('page_id' => $id)
)->execute();
$entity->markAsCreated($id, $this->getTable(), $this->connection);
return $id;
} else {
...
}
}
}2) zdá se mi, že v datech entity je trochu bordel – mám vícejazyčnou entitu
/**
* @property int $id
* @property DateTime $datetimeFrom|null (datetime_from)
* @property string $lang
* @property string $title
* @property string $text
*/
class Content extends \LeanMapper\Entity {
// id a datetime_from jsou v tabulce content, zbytek v content_text
}Tu načtu pomocí tebou navrženého způsobu za použití filtru a upravím
$content = $this->repository->find($contentId, 'cs');
$content->title = 'title ' . date('d.m.Y H:i:s');
$content->datetimeFrom = new \DateTime;Zajímavý je co se stane s daty týkajícími se property datetimeFrom.
getData a getModifiedRowData vrací správné
výsledky, getRowData to ale nějak míchá dohromady:
dump($entity->getRowData());
array(9) {
id => "3"
datetime_from => NULL
lang => "cs" (2)
alias => "test" (4)
title => "title 18.06.2013 14:35:21" (25)
description => ""
keywords => ""
text => "test" (4)
datetimeFrom => DateTime(3) {
date => "2013-06-18 14:35:21" (19)
timezone_type => 3
timezone => "Europe/Prague" (13)
}
}Je tam jak datetime_from = null, tak datetimeFrom s hodnotou. Buď by tedy měla metoda pracovat jen s nízkoúrovňovými daty nebo jen s vysokoúrovňovými – teď je tam oboje.
Díky.
před 6 lety
- Tharos
- Člen | 1042
@Filip111: Ahoj,
celé jsem si to prošel a jsem přesvědčen, že problém bude ještě
někde jinde. Tu ukázku, co jsem pro Tebe připravil, jsem zaktualizoval tak,
aby běžela na aktuální dev verzi Lean Mapperu (což obnášelo pouze
přejmenovat volání metody getModifiedData na
getModifiedRowData) a vše v ní funguje. Tady je ta upravená
verze .
Metoda getModifiedData se skutečně
pouze přejmenovala na getModifiedRowData. Nadále pracuje na
nízké úrovni.
Zkontroluj, prosím, svůj kód podle toho mého balíčku. V kódu, který jsi sem vložil, vidím nějaké odchylky, třeba tohle je nevalidní definice entity:
@property DateTime $datetimeFrom|null (datetime_from)Správně má být samozřejmě:
@property DateTime|null $datetimeFrom (datetime_from)Není náhodou zakopaný pes tady? :)
Pokud bys chtěl, pošli mi balíček s vybranými třídami, které používáš, a já se na to rád podívám. Zatím jsem přesvědčenej, že mnou navržené řešení je nadále funkční. :) Viz upravený balíček, na který odkazuji.
Edit: Tak jsem to teď krokoval a jsem si jist, že chyba je v té anotaci :). Vyzkoušej to prosím… Otázkou je, zda neupravit ten parser, aby tohle prostě spadlo.
Editoval Tharos (18. 6. 2013 15:44)
před 6 lety
- Tharos
- Člen | 1042
Šaman napsal(a):
Mám to okořeněné špetkou magie a použití se již blíží přesně tomu, jak bych si jednoduchý ORM představoval:
BaseRepository navíc u mě umí dotazy jako
getByEmail($email), nebofindByAuthorAndGenre($author, $genre), pokud jsou tyto metody uvedeny v anotacích (což zajišťuje i našeptávání). Get mi vždy vrací jedinou entitu, find vždy kolekci.BaseCollection umí
->fetchPairs($col1, $col2)a asi ho doučím ještě řazení a limity.BaseEntity mi implementuje rozhraní IResource, takže napojení na ACL je velmi jednoduché.
Jsem moc rád, že to vše šlo naimplementovat. Takhle přesně jsem si to
představoval. Třeba mně se magické metody findByXyz() také
líbí, ale do jádra ORM to IMHO nepatří, protože to zdaleka ne každý
využije a dá se to snadno dodělat v BaseRepository. To samé je
metoda fetchPairs.
Mou snahou je, aby se podobné věci právě velmi snadno doimplementovaly v abstraktních „base“ třídách. Je pro mě dobrá zpráva, že to lze snadno a ORM nehází klacky pod nohy. :) A díky za inspiraci.
před 6 lety
- Šaman
- Člen | 2275
Tharos napsal(a):
Šaman napsal(a):
Tohle zas tak moc nebolí, ale bylo by fajn, kdybych nemusel přetypovávat při každém přiřazení, ale pokud by tato metoda nedostala pole, ale bylo by splněné rozhraní, tak by si sama přetypovala ‚$values = (array) $values‘
Tak jsem podporu pro tohle nakonec přidal. Ukázka použití je zde.
Ve spojení s výše uvedenou
BaseEntityby tedy mělo být možné vytvářet entitu z dat z formuláře i včetně 1:N závislostí následovně:$book = new Book($form->getValues()); // $bookRepository->persist($book); // echo $book->author->name; // vypíše název autoraCož je skoro návykové, já uvedenou
BaseEntityasi taky budu používat :).
Mohl bys to ještě přidat pro assign? V editačních formulářích musím
stále přetypovávat.
Prozatím jsem to pořešil v BaseEntity, ale musel jsem odstranit
v LeanMapper\Entity podmínku, že předávaný parametr je array (když
v potomkovi změním typ parametru, hází to strict error).
S těmi array v definici funkce opatrně, s tím už se
v potomkovi nehne.
Z jiného soudku: mohu nějak zjistit na jaký sloupec se mapuje která
property?
(př. mám entitu $book a název ‚author‘ a vím, že je to
proměnná. Potřebuji vrátit ‚author_id‘, tedy název příslušného
sloupce. Využití by bylo, když řeším
findByAuthor($author)).
Začal jsem používat ten whitelist u assign. Sikovná věcička, ale trochu mi chybí u vytváření nové entity. Ale to je detail, který se dá lehce obejít.
Editoval Šaman (18. 6. 2013 21:34)
před 6 lety
- Filip111
- Člen | 244
@Tharos:
Ano, bylo to chybnou definicí v anotaci. Byl bych pro, přidat kontrolu do
parseru, aby to vyhodilo nějakou výjimku při chybné definici property.
Strávil jsem nad tím tak hodinu :) – nadefinoval jsem si celou entitu s asi 15-ti vlastnostmi a hrozně se divil, když mi mapper házel výjimku, že hodnota nemůže být null, přestože jsem property zadefinoval jako null. Měl jsem to zase zadefinované po svém…tedy blbě.
Díky.
před 6 lety
- Filip111
- Člen | 244
@Tharos:
zpátky k překladům :)
Protože potřebuji zjednodušit metodu persist a neuvádět tam seznam DB
sloupců z jednotlivých tabulek (hlavička versus překlad) – snažím se
to dostat do nějakého předka TranslatableRepository, který si obě tabulky
obhospodaří sám.
Napadlo mě to udělat automaticky pomocí anotace, takže např sloupec z tabulky překladů by byl zadefinován
* @property string $text translatablenamísto
* @property string $textPotom bych všechny property bez translatable příznaku uložil do tabulky hlaviček a všechny property s translatable příznakem do tabulky textů.
Zatím se ale nedokážu dostat z repository k anotacím – šlo by to
nějak? Našel jsem jen nějaké getReflection v
private $internalGetters = array('getData', 'getRowData', 'getModifiedRowData', 'getReflection');ale v getteru je poznámka
// TODO: find better solution (using reflection)
Měl bys nápad jak na to, případně jestli by to mohla být správná
cesta?
Mám vůbec šanci se dostat k anotacím, které nepodporuješ?
Editoval Filip111 (18. 6. 2013 21:53)
před 6 lety
- Tharos
- Člen | 1042
Šaman napsal(a):
Mohl bys to ještě přidat pro assign? V editačních formulářích musím stále přetypovávat.
Tak jsem to přidal (do develop větve). Dává smysl, aby to
metoda assign také uměla – takhle je to konzistentní
s konstruktorem.
Z jiného soudku: mohu nějak zjistit na jaký sloupec se mapuje která property?
(př. mám entitu$booka název ‚author‘ a vím, že je to proměnná. Potřebuji vrátit ‚author_id‘, tedy název příslušného sloupce. Využití by bylo, když řešímfindByAuthor($author)).
Rozumím. Lze to vyřešit následovně:
abstract class BaseEntity extends Entity
{
public function readColumn($property) // záměrně není pojmenovaná getColumn, protože to není getter položky
{
$property = $this->getReflection()->getEntityProperty($property);
if ($property === null) {
return null;
}
if ($property->hasRelationship()) {
$relationship = $property->getRelationship();
if (!($relationship instanceof HasOne)) {
return null; // or throw some exception
}
return $relationship->getColumnReferencingTargetTable();
} else {
return $property->getColumn();
}
}
}Nerad bych tohle přidával úplně do jádra knihovny, protože to trochu
hraničí s porušením zapouzdření. Entita by měla skrývat vnitřní
reprezentaci dat jak jen to je možné. Ale protože víš, co děláš, v
BaseEntity to můžeš snadno vyřešit výše uvedeným
způsobem.
Začal jsem používat ten whitelist u assign. Sikovná věcička, ale trochu mi chybí u vytváření nové entity. Ale to je detail, který se dá lehce obejít.
Tohle bych do jádra také nerad přidávat. Konstruktor entity už by pak
byl vážně překombinovaný. Tohle lze, jak jistě víš :), opět řešit
přes BaseEntity.
před 6 lety
- Tharos
- Člen | 1042
@Filip111:: Já bych tyhle anotace dělal nad repositářem. Tam ideálně patří.
Rozdělit uložení do více tabulek je totiž záležitost repositáře.
Entity sice v anotacích mohou obsahovat „názvy databázových sloupců“,
ale píšu to v uvozovkách, protože to není úplně přesné. Ony jsou to
totiž názvy položek v LeanMapper\Row (které zapouzdřuje
LeanMapper\Result).
To, do jaké tabulky se položky z Row
persistují, je rozhodně záležitost repositáře.
Jinými slovy… Můžeš si představit následující vrstvy:
| Entita |
| Row |
| DB sloupec |
To, do jakých databázových sloupců a tabulek se rozloží hodnoty z
Row, by měl řešit repositář. Například takový:
/**
* @translatable(perex,content)
*/
class PageRepository extends BaseRepository
{
}Stačí takovéto navedení? :)
Edit: Nahradil jsem v příspěvku instance
Result za Row. Je sice pravda, že Result
udržuje vlastní data, ale Row jej velmi důsledně zapouzdřuje.
Programátor tak v praxi nepřijde s třídou Result nikdy
přímo do styku (snad kromě nějakého ručního vytváření). Zpravidla
k instanci Result přistupuje skrze instanci Row.
Editoval Tharos (19. 6. 2013 0:18)
před 6 lety
- Šaman
- Člen | 2275
Tharos napsal(a):
(zjištění názvu sloupce z jména property)
Nerad bych tohle přidával úplně do jádra knihovny, protože to trochu hraničí s porušením zapouzdření. Entita by měla skrývat vnitřní reprezentaci dat jak jen to je možné. Ale protože víš, co děláš, vBaseEntityto můžeš snadno vyřešit výše uvedeným způsobem.
S tímhle moc nesouhlasím. Pokud by entita byla skutečně čistě jen OOP entita, tak ano. Ale entita má v sobě kus mapperu (právě to mapování sloupců). A druhá část mapperu je v repozitáři (pokládání dotazů). K pokládání dotazů potřebuji znát mapování sloupců, takže repozitář se musí být na tohle schopen zeptat.
Dokonce si myslím, že je špatné pokládání dotazů s přímým vypisováním názvů sloupců. Tato informace se stává redundantí (v entitě a ve spoustě dotazů v repu) a pokud v entitě změním mapování, nebude to mít na dotazy vliv. Ideální by bylo, kdyby při změně názvu sloupce v databázi stačilo přepsat název sloupce v anotaci v entitě. A alespoň většina dotazů by to měla zohlednit (výjimkou jsou složité dotazy, které si holt bude muset programátor upravit sám).
Takže podle mě entita musí umožnit repozitáři nahlédnout pod pokličku, je to daň za neexistující samostatnou mapovací vrstvu.
Tharos napsal(a):
(whitelist v konstruktoru entity)
Tohle bych do jádra také nerad přidávat. Konstruktor entity už by pak byl vážně překombinovaný. Tohle lze, jak jistě víš :), opět řešit přesBaseEntity.
Souhlasím – přesně z důvodu překombinovanosti konstruktoru to neřeším přes BaseEntity, ale vytvořením prázdné entity a následným assign. Ušetření řádku na úkor čitelnosti by nebylo dobré.
Jenom přemýšlím jestli si neudělat alias
assign() -> setData() – přijde mi to intuitivnější.
A proměnnou $data si stejně jednoduše udělat nemohu, protože
mi ji blokuje getData().
Editoval Šaman (19. 6. 2013 0:53)
před 6 lety

- Glottis
- Člen | 129
Šaman napsal(a):
Tharos napsal(a):
(zjištění názvu sloupce z jména property)
Nerad bych tohle přidával úplně do jádra knihovny, protože to trochu hraničí s porušením zapouzdření. Entita by měla skrývat vnitřní reprezentaci dat jak jen to je možné. Ale protože víš, co děláš, vBaseEntityto můžeš snadno vyřešit výše uvedeným způsobem.S tímhle moc nesouhlasím. Pokud by entita byla skutečně čistě jen OOP entita, tak ano. Ale entita má v sobě kus mapperu (právě to mapování sloupců). A druhá část mapperu je v repozitáři (pokládání dotazů). K pokládání dotazů potřebuji znát mapování sloupců, takže repozitář se musí být na tohle schopen zeptat.
Dokonce si myslím, že je špatné pokládání dotazů s přímým vypisováním názvů sloupců. Tato informace se stává redundantí (v entitě a ve spoustě dotazů v repu) a pokud v entitě změním mapování, nebude to mít na dotazy vliv. Ideální by bylo, kdyby při změně názvu sloupce v databázi stačilo přepsat název sloupce v anotaci v entitě. A alespoň většina dotazů by to měla zohlednit (výjimkou jsou složité dotazy, které si holt bude muset programátor upravit sám).
Takže podle mě entita musí umožnit repozitáři nahlédnout pod pokličku, je to daň za neexistující samostatnou mapovací vrstvu.
na tom neco je :)
ad whitelist: me teda spis vzdicky uspokojil blacklist. vetsinou bylo jen par sloupcu co nechci nez vypisovat ty co chci. ale asi to bude tak 50 na 50 :)
před 6 lety
- Tharos
- Člen | 1042
@Šaman: Rozumím. Díky za pohled na věc zase z jiného úhlu – teď si myslím, že ve značné míře tohle vyřeší zavedení konvencí plánované do verze 1.5. :)
Pak se jen v repositáři zeptáš té třídy s konvencemi, jejíž instancí bude repositář disponovat.
Edit: No, ještě jsem si to nechal uležet a v některých případech to samospásné taky nebude – konvence samy o sobě například nepoznají, jestli nějaká položka obsahuje nebo neobsahuje vazbu.
OK. Svým vysvětlením jsi mě přesvědčil, že o vyloženě hřích
proti zapouzdření nejde. Zatím bych to ale nechal na BaseEntity
(ta může umět vrátit třeba celou sadu
LeanMapper\Reflection\Property – tyhle třídy jsou beztak read
only) a časem bych zvážil, jestli něco takového přidat nebo nepřidat do
jádra. Využití je specifické.
Editoval Tharos (19. 6. 2013 9:10)
před 6 lety
- Tharos
- Člen | 1042
@Glottis: U blacklistu je problém, že do něj snadno zapomeneš něco vepsat. Ne třeba při prvotní definici, ale například časem při přidání nějakého vstupu do formuláře. Přidáš ho do formuláře, ale už ho třeba zapomeneš přidat do blacklistu. Může tak vzniknout dost nenápadná chyba. Pokud něco potřebného nepřidáš do whitelistu, zpravidla se o tom dozvíš okamžitě.
Editoval Tharos (19. 6. 2013 10:42)
před 6 lety
- Filip111
- Člen | 244
@Šaman, @Tharos:
Zrovna včera, když jsem řešil podivné výsledky getRowData()
mě napadlo, jestli je vůbec správné pracovat v repository s názvy DB
sloupců namísto jména property. Protože ale v repository skládám přímo
dotaz pomocí dibi, jiná možnost není…přesto u Doctrine se v repository
pracuje s názvy property, takže člověk je na to trochu navyklý.
Takhle je potřeba opravit/měnit název sloupce jak v entitě, tak repository,
což není ideální.
@Tharos:
U anotace translatable platí to samé co jsem teď zmínil – pokud budu
anotaci definovat v repository, budu muset při změně/rozšiřování entity
upravit jak entitu, tak anotaci v repository. Zatímco při definici anotace
v entitě, jen přidám nový sloupec v entitě včetně anotace translatable
a repository si to už samo rozháže do příslušných tabulek.
Asi to není správně řešení z pohledu návrhových vzorů apod., ale
přijde mi to praktické
(a i když nechci z LeanMapperu dělat Doctrine :), neodpustím si zase
srovnání – tam se definuje translatable anotace v entitě (Gedmo
extension).
Editoval Filip111 (19. 6. 2013 9:23)
před 6 lety
- Tharos
- Člen | 1042
@Šaman, @Filip111: Nedáme nějaký hromadný Skype?
Tenhle problém je o nalezení „optimálního kompromisu“. Proti sobě tak trochu stojí tenkost (a v důsledku i ohybatelnost) versus míra abstrakce… Myslím, že průnik našich pohledů/požadavků by mohl vést k dobrému řešení.
Kdyžtak napište přes SZ. Díky :).
Editoval Tharos (19. 6. 2013 10:10)
před 6 lety
- Šaman
- Člen | 2275
@Tharos: Konvence to nevyřeší – ty jen
způsobí, že se bude ruční mapování používat jen vzácně a proto tento
problém nebude tak pálit. Stále by ale poslední slovo měla mít entita
(resp. to místo, kde si mohu konvence upravit).
Kdyby si entita nekladla vlastní dotazy (přes row), tak by se dalo mapování
přenést do repozitáře (mapperu), ale takhle ta ta provázanost
bude nutná.
před 6 lety
- Filip111
- Člen | 244
@Tharos:
zase otravuju :)
Zkouším zadefinovat entitu včetně vazeb a hned jsem se zasekl na první –
jedu již na existující DB struktuře, takže nedodržuji tvoje konvence –
sloupec gallery odkazuje do tabulky gallery na id.
Pak mám ještě zadefinovanou entitu Gallery, ale tam zatím není nic zajímavého.
Problém je v tom, že mapper mi padá na
Undefined index: gallery_id. Vysledoval jsem to až k vytváření
vazby hasOne a špatně se tam předává referenční sloupec z první tabulky
(tedy gallery_id namísto gallery).
V dokumentaci jsem našel, že by měl fungovat v definic vazby anotací
dodatek (sloupec odkazující na cílovou tabulku:cílová tabulka)
ale nějak mi to nefunguje.
Zkoušel jsem:
* @property Gallery|null $gallery m:hasOne
* @property Gallery|null $gallery m:hasOne (gallery)
* @property Gallery|null $gallery m:hasOne (gallery:galery)Jen doplním i zkrácený zbytek Content entity:
/**
* @property int $id
* @property Gallery|null $gallery m:hasOne (gallery)
* @property bool $status
*/
class Content extends \LeanMapper\Entity {
}Díky.
ps.:
Podařilo se mi v repository zprovoznit anotace pro identifikaci translatable
sloupců
/**
* @translatable(alias,title,description,keywords,text)
* @translationTable(content_text)
*/Plus zobecnil jsem filtr joinTranslation aby používal tabulku
@translationTable a vše přesunul do TranslatableRepository. Pokud
nad tím postavím jednoduché repository jen s anotací, tak to kupodivu
funguje. Trochu to ještě otestuji a upravím a pak to sem třeba hodím. Je
otázka jestli to dále zobecnit a rozvinout – zatím tam jsou zadrátované
moje konvence, jako např. sloupec lang, nebo spojení hlavičky s překladem
pomocí sloupce id: content.id = content_text.id (cotent_text má složený
primární klíč id a lang).
před 6 lety
- Tharos
- Člen | 1042
@Filip111: Zkus přepsat:
@property Gallery|null $gallery m:hasOne (gallery)na následující:
@property Gallery|null $gallery m:hasOne(gallery)Všimni si odstraněné mezery mezy m:hasOne a závorkami… Přiznávám, že je to hrozný :). Asi s tím parserem budu muset něco udělat… Ale bude to oříšek, protože on záměrně nechává například prostor pro komentář k property a těžko pozná, jestli mezerou oddělené (gallery) není už třeba nějaký komentář. :/
To je prostě bída toho programování v anotacích…
Ad překlady) Tak super, jsem rád, že to takhle šlo. Mně
napadla ještě jedna věc… Mohl by existovat příznak m:extra(), který by
mohl obsahovat libovolnou hodnotu a tu by poté šlo získat z
LeanMapper\Reflection\Property. Takže Ty bys ten příznak mohl
využít například u překladatelných položek /m:extra(translatable)/
s tím, že bys pak jen v BaseEntity měl metodu, která by Ti
uměla vrátit přehled překladatelných položek. Toho by se pak snadno
využilo v repositáři, takže by všechny definice byly na jednom místě
v entitě.
Co si myslíš o podobném řešení? Tímto stylem by anotace daly snadno obecně rozšiřovat.
Editoval Tharos (19. 6. 2013 15:17)
před 6 lety
- Filip111
- Člen | 244
@Tharos:
Tak po odmazání mezery vazba skutečně funguje – jsou to takový
dětský nemoci a trochu kazí celkový dojem. Zase bych se přikláněl
k nějaký kontrole – řekněmě, že validní zápis bude jen bez
mezery.
Nebylo by lepší předělat komentáře např. vše za // bude komentář a
naopak zlepšit kontrolu zápisu v anotaci? Mám na to asi smůlu, ale už jsem
na to narazil podruhý a pokaždý je to WTF.
Ad překlady:
Pro mě by to bylo lepší – pořád jsem se nevzdal myšlenky umístit
označení translatable do definice property v entitě. Koneckonců obecný
příznak by se mohl hodit komukoliv dalšímu. Rovnou bych počítal s tím,
že v extra bude moci být uvedeno více příznaků.
Editoval Filip111 (19. 6. 2013 15:48)
před 6 lety
- Tharos
- Člen | 1042
@Filip111: Určitě ten parser vylepším. Praxe ukazuje, že to nebude zbytečně vynaložená energie.
před 6 lety
- Tharos
- Člen | 1042
Pokusil jsem se vyloženě skepticky nahlédnout na současný návrh knihovny a problém zde propíraného mapování. Zároveň jsem zvážil hned několik alternativ… abych se nakonec zase utvrdil v tom, že současný přístup představuje velmi dobrý kompromis mezi množstvím požadavků, které u ORM prostě nelze dokonale uspokojit zároveň (tenkost, míra abstrakce, možnosti, výkon…).
To, že Lean Mapper vychází z trochu odlišného paradigma než třeba taková Doctrine 2, je fakt. Dalším faktem je, že mnozí mají styl myšlení ala Doctrine 2 zakořeněný, a tím logicky vznikají jistá nedorozumění. :)
Entity v Lean Mapperu jsou jakési obálky nad instancemi Row.
Každý takový Row obsahuje low-level položky a data. To, že
Row ta data nemá přímo u sebe a zapouzdřuje jakýsi
Result, který shromažďuje na jednom místě více
souvisejících dat, teď není podstatné. To je jenom nějaký vnitřní
balast, se kterým programátor vůbec nepřijde do styku a který je tam
primárně proto, aby bylo možné klást dotazy ve stylu NotORM.
Row tedy obsahuje jakousi relaci, kterou entita potřebuje
k životu. Každá entita vyžaduje Row o určité struktuře.
Dá se tedy říct, že struktura konkrétního Row vytváří
jakési rozhraní. Entita má za úkol poskytnout navenek
hezké objektové API a také má za úkol umět transformovat příchozí
vysokoúrovňová data (typicky hodnoty nebo jiné entity) do
nízkoúrovňových dat, které mohou být uloženy v Row.
Úkolem repositáře je mimo jiné získat z databáze takovou relaci, ze
které bude možné vytvořit Row s tou požadovanou
strukturou (a takový Row poté obalit entitní
třídou).
Row má v tomhle směru skutečně charakter
rozhraní. Z toho ale plynou určité důsledky. Například to, že
když se změna názvu sloupce občas promítne do repositáře i do entity,
nejde o katastrofu, protože to je úplně stejná situace, jako když se
někde změní rozhraní: musí se upravit jak všechny implementace rozhraní
(analogie k repozitáři), tak i všechna použití takového rozhraní
(analogie k entitě). Nedá se tedy říci, že by bylo něco vyloženě
duplicitní nebo špatné.
Důležité je také uvědomit si, že položka v Row nemusí
být reprezentovaná jenom sloupcem v databázi. Může jít například
o výsledek nějaké agregační funkce volané v databázi. Obávám se tedy,
že Mapper, který by mapoval databázové sloupce na položky, by potenciál
Lean Mapperu dost omezil.
Z tohohle mi vyplývá několik důsledků…
1) Definice „sloupců“ v anotacích v entitě není
vůbec nijak závadná, protože ono to ve skutečnosti není provázání
položek entity s nějakými sloupci v databázi, ale s položkami v
Row.
2) Vynesení LeanMapper\Reflection\Property ven
z entity (například v nějaké BaseEntity) není porušením
zapouzdření, protože entita nad Row vytváří veřejné API,
které rozhodně není tajné a vynesení této Property jen
usnadňuje analýzu a strojové zpracování toho API.
Přímo do entity v jádru Lean Mapperu bych ale pro tohle vynesení podporu
nepřidával, protože každý to bude chtít provést jinak – někdo podle
názvu položky, jiný zase bude chtít vynést ty Property, které
mají příznak m:extra(translatable)… Tudíž bych nechal
„vynesení“ na každém podle jeho chuti.
3) Mappery nechybí, protože namísto jich jsou
v knihovně přítomná jakási rozhraní daná používanými
Row. Je to jen jiný přístup k problému.
Vítám oponenturu :).
Editoval Tharos (19. 6. 2013 18:53)
před 6 lety
- Tharos
- Člen | 1042
Filip111 napsal(a):
Rovnou bych počítal s tím, že v extra bude moci být uvedeno více příznaků.
Navrhuji udělat to tak, že vše, co bude uvnitř
m:extra(......), prostě půjde přečíst přes
$property->getExtra(). Někdo to může využít pro
m:extra(translatable), jiný pro
m:extra(book#hello::something) a dál si to zparsuje podle svého
gusta (potřeb).
Editoval Tharos (19. 6. 2013 18:24)