Oznámení
Lean Mapper – EntityFactory RFC
před 6 lety

- Tharos
- Člen | 1042
Ahoj,
mám jedno takové RFC týkající se Lean Mapperu…
Diagram tříd (nebo alespoň jeho „náčrtek“) vypadá nyní zhruba následovně:
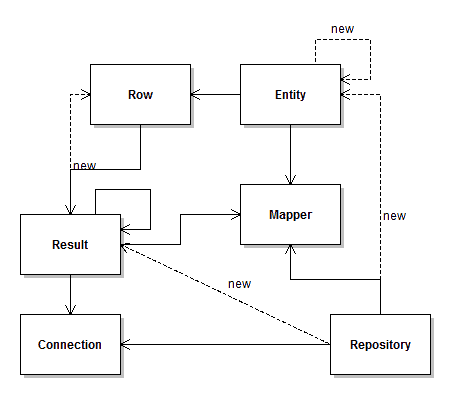
No a já zvažuji, že by od verze 2.1 vypadal následovně:
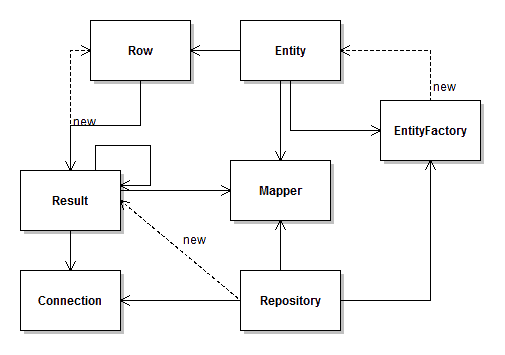
Jediným rozdílem je nová část EntityFactory. Jaký je její
význam?
Jak bylo probíráno zde, model postavený nad Lean Mapperem trochu svádí k tzv. anémickému modelu. Ono to není až takové neštěstí, IMHO naprostá většina webů nemá tak košatou doménovou logiku, aby její vyjádření striktně v duchu Domain-driven Designu přinášelo nějaké zásadní výhody, navíc většina webů je IMHO dost data-centric, kde to tuplem nevadí…
Nicméně pokud by někdo přece jenom ucítil potřebu injectovat do entit
i nějaké další doménové objekty (nějaké mailery, loggery), byl bych moc
rád, kdyby mu to Lean Mapper umožnil. A řešila by to právě
EntityFactory.
Její zodpovědností by samozřejmě bylo vytvořit instanci požadované
entity z dodaného LeanMapper\Row. Důležité je, že by ta
factory mohla vytvořené entitě injektovat další závislosti (zmíněné
mailery, loggery atp.).
Také mě na tom láká to, že by se vytváření instancí entit přesunulo na jedno jediné místo.
Moc by se mi líbilo, kdyby EntityFactory uměla do právě
vytvořené entity injektnout služby pomocí auto-wiringu přímo ze
systémového kontejneru. Implementačně by to bylo úplně triviální.
Nějaká konkrétní entita by pak mohla vypadat například následovně:
/**
* @property int $id
* @property User $owner m:hasOne
* @property DateTime $created
* @property string $description
* ...
* ...
**
class Order extends LeanMapper\Entity
{
/** @var Logger */
private $logger;
/**
* @var Logger $logger
*/
public function inject(Logger $logger)
{
$this->logger = $logger;
}
public function logState()
{
$this->logger->logOrderState($this);
}
}Takto navržený model má své výhody i nevýhody, které bych zde nerad rozebíral. :)
Výchozí implementace nějaké IEntityFactory by ale to
injektování samozřejmě nedělala – to injektování už by záviselo na
použitém DI frameworku.
Co si o tom myslíte? Zásah by to byl velmi kosmetický, i když lehce zpětně nekompatibilní (proto bych to cílil do verze 2.1).
před 6 lety

- Casper
- Člen | 253
Můžu říci snad jen jediné: už aby to bylo :) Jak jsem již párkrát zmínil, tohle prostě v LM chybělo a je super, že pro to plánuješ podporu. Pokud bude skutečně vše fungovat plně automaticky pomocí DIC, nemám výhrad :)
před 6 lety

- Šaman
- Člen | 2275
Za mě palec nahoru. Jen bude potřeba trocha edukační činnosti, aby někdo nezkoušel do entity cpát věci, které do ní evidentně nepatří. Ale zatím u mě LM překonal očekávání :)
před 6 lety
- Tharos
- Člen | 1042
@Šaman: Toho si opravdu vážím, že dokonce překonal. To víš, nezavděčil jsem se všem … :)
Co se edukace týče, tohle bych skutečně nechal ležet ladem jako funkcionalitu pro ty, kteří ví, co s ní. A to na vlastní nebezpeční. :)
Mimochodem, díky této separaci se otevírá prostor více zajímavým věcem. Jelikož vznik všech entit bude řízen z jednoho místa, nabízí se možnost implementace Unit Of Work a také omívané Identity Map. :) V jádru se ale do nich pouštět nebudu – ono to totiž bude možné komplětně vyřešit formou nadstavby.
Mám pár postřehů k té Identity Map. S ní zůstává jeden principiální problém – kvůli NotORM-like čtení si entity musí udržovat určitý kontext (Result). Problém je, že v aplikaci mohou vzniknout například dva články s ID 1, ale každý vznikne v jiném kontextu. Kdybych při vytváření té druhé entity kompletně zrecykloval tu první, již vytvořenou, narazil bych při dalším traverzování, protože bych právě narušil ten koncept kontextů. Tohle je hlavní (a asi jediný) problém, proč je identity mapa obtížně slučitelná s NotORM-like čtením (má-li být řešení tenké, ono by samozřejmě i tohle šlo nějak vyřešit). Neříkám ale, že to úplně pouštím z hlavy.
Mimochodem ta Unit Of Work by mohla být implementačně
dost jednoduchá a to bych si možná i sám naimplementoval kvůli pohodlí.
Abych když mám vytaženou nějakou entitu, něco v ní upravím, pak přes
ní zatraverzuji po nějakých souvisejících entitách a také v nich něco
upravím… abych pak jenom zavolal nějaké
$unitOfWork->flush() a nemusel ručně každou tu upravenou
entitu persistovat nad jejím repositářem. To by také myslím mohlo být
velmi příjemné.
před 6 lety

- hrach
- Člen | 1810
<offtopic>jsem slavný</offtopic>
před 6 lety
- Šaman
- Člen | 2275
Nemá cenu tu argumentovat pro a proti – LM, nebo NDb, nebo NotORM, nebo
Dibi, nebo Doctrine2.
Pro mě je důležité, že se mi LM používá dobře a stále má rezervy
v tom, co bych mohl udělat, kdybych potřeboval nějakou optimalizaci.
Klíčové bude dotáhnout dokumentaci, spoustu možností jsem zjistil až z videa. A máš někde ukázku toho QueryObjectu? I podle komentů u ukázkové aplikace bych ho měl co nejdříve nasadit.
Editoval Šaman (1. 11. 2013 21:49)
před 6 lety

- Pavel Macháň
- Člen | 285
Šaman napsal(a):
Nemá cenu tu argumentovat pro a proti – LM, nebo NDb, nebo NotORM, nebo Dibi, nebo Doctrine2.
Pro mě je důležité, že se mi LM používá dobře a stále má rezervy v tom, co bych mohl udělat, kdybych potřeboval nějakou optimalizaci.Klíčové bude dotáhnout dokumentaci, spoustu možností jsem zjistil až z videa. A máš někde ukázku toho QueryObjectu? I podle komentů u ukázkové aplikace bych ho měl co nejdříve nasadit.
před 6 lety

- llook
- Člen | 412
Nějak se mi nezdá, jakým způsobem se EntityFactory předává do Repository. Takto teoreticky může dojít k tomu, že se s jedním Connection budou používat různé EntityFactories. Zapomeneš u jednoho repa předat EntityFactory a část entit v systému bude používat DefaultEntityFactory…
Možná už je na čase zavést nějaký „hlavní objekt“, něco jako EntityManager v Doctrine2. Tento objekt by pak poskytoval všechno, co potřebují všichni stejné – v tuto chvíli Connection a EntityFactory.
ad Query Object) Když to srovnám s Fowlerovým Query Objectem, tak ten tvůj by se spíš měl jmenovat Criteria. Úlohu Query Objectu v tvém případě ve skutečnosti přebírá Repository. To je z více důvodů špatně, moc bych to nedoporučoval.
před 6 lety
- Tharos
- Člen | 1042
@llook: Díky za samé dobré přípomínky.
Ad předávání EntityFactory) Pozor, ten
parametr v Repository je povinný, nelze jej zapomenout. Neplatí,
že by se v případě nepředání EntityFactory automaticky
použila DefaultEntityFactory.
Vím, že čistě teoreticky lze každému repositáři předat jinou
EntityFactory, ale myslím si, že tenhle omyl snad nemůže nikdo
udělat ani v dobré víře. Stejně to funguje i s mapperem, který se
předává v podstatě identicky. Také lze čistě teoreticky různým
repositářům předat různé mappery, ale nedokážu si představit, jak by se
tohle někomu svéprávnému omylem povedlo. Ale možná se pletu?
Ad „hlavní objekt“: To je právě otázka. Už jsem nad
tím také uvažoval – takový objekt by mohl poskytovat
Connection, IMapper a IEntityFactory.
Předávání by pak byla jedna báseň. Jenomže mně na tomhle vadí hned
několik věcí:
- Netvrdím, že by to byl nějaký God object, on by jen zpřístupňoval zapouzdřené služby, ale cítím v tom jistý nádech… jekéhosi service locatoru, viz dále.
- Skrývá to závislosti. Když vím, že
Repositoryje závislé naConnection,IMapperaIEntityFactory, vím vše. Dokonce si dokážu snadno domyslet, co k čemu potřebuje –Connectionk načítání dat z databáze,IMapperpro detaily O/R mapování aIEntityFactorypro vyrábění instancí entit. Zatímco když vím, že závisí na nějakémLeanMapper\Managernebo na něčem podobném, musím zkoumat kód, abych se dozvěděl, co Repository skutečně potřebuje.
Mně osobně třeba EntityManager z Doctrine až tak
neoslnil… Jako spousta jiných managerů. Skoro mi přijde, že
jakmile název třídy obsahuje slovo manager, tak už
zavání. :)
3. Nezabrání to vzniku nekonzistence napříč mappery, továrnami na
entity… Když budu chtít, stejně do repository „A“ předám jiný
LeanMapper\Manager (rozuměj s jiným obsahem) než do repository
„B“. Otázkou samozřejmě je, proč bych to dělal. Tady myslím
k vysvětlení nestačí ani ten dobrý úmysl. :)
Proto se mi prostě současné předávání závislostí líbí víc (je plně v duchu DI). Ale třeba se ještě někdo ozve a převáží mé argumenty, jsem naprosto otevřen diskuzi.
Ad Query Object: Máš naprostou pravdu, vím, že nejsem
s Fowlerem kompatibilní (vlastně už jsem to tu na fóru někde i psal).
Proto ten svůj Query zatím nikde až ten neventiluji, protože
jej nechávám dozrát. Název Criteria by asi lépe vystihoval
podstatu věci.
Aby to byl Query Object ala Fowler, musel by se sám umět
přeložit do… čehosi. Zde asi do sekvence volání nad
DibiFluent. To by neměl být až takový problém, ale řešení,
kdy ten objekt nese jenom objektovou reprezentaci nějakých restrikcí, mi
přijde „stravitelnější“. Je to jako SQL samotné: já píšu SQL kód,
který interpretuje databáze. Zde nastavuji nějaká kritéria, která
interpretuje repositář.
Jaké jsou přesně ty důvody, proč je tohle špatně? Kdy se s tímhle dá narazit? Tohle téma mě vážně zajímá, předem díky za rozvinutí diskuze. :)
před 6 lety
- Šaman
- Člen | 2275
Ohledně různých Mapperů pro různé Repository: Tohle se
náhodou hodí. Nezkoumal jsem poslední dobou zdrojáky, ale mám v plánu
zkusit si vytvořit nějaké <EntityName>Mappery pro
případné výjimky oproti hlavnímu mapperu. Teď mám možnost takové
výjimky popsat přímo v entitě (což se mi moc nelíbí), nebo ifovat
v mapperu. Pokud podědím mapper a nastavím mu nějaké výjimky pro
konkrétní entitu/repostiory, bude to přehlednější (takže budu mít třeba
User – UserRepository – UserMapper). Pokud žádné výjimky nejsou,
stačí nám základní mapper (anebo bude UserMapper prázdný, ale
připravený pro možnost změn mapování.)
Různé repository pro jinou instanci entity stejné třídy
si také dovedu představit, ale už jen výjimečně. Občas potřebuji třeba
místo mazání záznamů (typicky uživatelů) jen nastavit příznak, že jsou
deaktivováni. V UserRepository chci ale pracovat jen s aktivovanými
uživateli, nějaký AllUserRepository bych pak použil jen pro uložení
deaktivovaného uživatele a v podobných speciálních případech. Přitom
UserRepository se bude lišit jen tím, že jeho query bude mít implicitně
nastavenou (ideálně nepřepsatelnou) podmínku, že
active = TRUE.
Mě osobně se velmi líbí, když repozitář umí pracovat jen s tím, co
mu vrátí jeho základní query/metoda findAll().
před 6 lety
- llook
- Člen | 412
Proč je to špatně:
- Repository získává novou odpovědnost, interpretaci kritérií. Když budeš chtít přidat třeba range restriction, tak budeš měnit jednak tu třídu Query, ale i Repository. Kdybych to dělal já, tak bych si přitom připadal, jako kdybych do jedné třídy dával jenom vlastnosti a do druhé jenom metody pro práci nad nimi.
- Vždycky budou dotazy, které budeš chtít položit, ale ten interpreter na ně bude krátký. Jak na ně? Budeš kombinovat přístup přes criteria objekty s findByBlabla metodami?
- A potom bych měl problém s univerzálními metodami typu
restrict('column', 'value'), protože znemožňují statickou analýzu a ztěžují refaktoring, otevírají prostor pro překlepy atd. Ale to se netýká principu „repository jako query object“, ale spíš obecných query objektů vůbec. K tomu se ještě vrátím.
Query Object, jak ho představuje Fowler, je objekt, který umí na základě nějakého svého nastavení vygenerovat dotaz. Jestli to nastavení představují nějaké high-level Criteria objekty, jako v tom jeho diagramu, nebo třeba obyčejné PHP array, na tom tak dalece nesejde. Různé query objekty to můžou mít různě složité, podle potřeby.
Mě dává smysl, aby repository pouze hloupě vracelo entity na základě SQL dotazu. Sestavení toho SQL dotazu, to ať dělá někdo jiný, query object:
public function find(IQuery $query)
{
return $this->createEntities(
$this->connection->query(
$query->createQuery($this->mapper)
)
);
}Může existovat i nějaký obecný query objekt pro prototypování. To by
byl třeba ten tvůj Query, kdybys mu přidal metodu
createQuery().
Obecný query objekt má ale jednu velkou nevýhodu – nemá jasně dané
rozhranní. Není zřejmé, že umí restrict('foo'), ale neumí
restrict('bar'), to zjistíš až za běhu. Taky to ztěžuje
refaktoring. Třeba budeš chtít smazat nepotřebný sloupec, ale jak
zjistíš, že je opravdu nepotřebný? Že v nějakém zapadlém zákoutí
aplikace podle něj něco nefiltruješ/neřadíš?
Pokud vím, tak tím si kdysi prošlo i PetrP/Orm – úplně magické
metody findByColumn byly ze začátku strašně pohodlné, časem
se ale stávaly přítěží a kvůli tomu se zavedla povinnost každou takovou
metodu přidat přes anotaci, jinak se k ní __call nezná.
Já jsem příznivcem toho, čemu říkám konkrétní query objekt. Typicky u jednoduchých aplikací bys měl jednu query třídu ke každému repository. Používalo by se to nějak takto:
$lastTenAuthorsArticles = $articles->find(
new Query\Articles\All()
->restrictAuthor($author)
->orderDescByCreatedAt()
->limit(10)
);Jak by aplikace rostla, tak by se vyčleňovaly opakující se dotazy do samostatných tříd, např.:
$lastTenAuthorsArticles = $articles->find(
new Query\Articles\LastByAuthor($author)
);
...
namespace Query\Articles {
class LastByAuthor extends All
{
public function __construct(Author $author, $limit = 10)
{
parent::__construct()
->restrictAuthor($author)
->orderDescByCreatedAt()
->limit($limit);
}
}
}Hlavní rozdíl je ten, že tohle má API. Můžeš v IDE zjistit, jestli se nějaká restrikce skutečně používá, můžeš snáz přejmenovávat, máš code-completion apod.
Takové základní věci, jako omezení podle sloupce nebo řazení by mohly být vyčleněné do nějakého společného předka a do konkrétních query tříd by se přidávaly nejsnáz asi anotacemi:
/**
* @method static restrictAuthor(Author $author)
* @method static restrictCategory($category)
* @method static orderDescByCreatedAt()
* atd...
*/
class Articles extends Query
{
}Takže ani toho psaní by nebylo nějak moc. Během parsování těch anotací by se navíc dalo kontrolovat, že nenabízí filtrování podle sloupce, který neexistuje.
To 1% dotazů, které je nutné psát ručně, by se zapouzdřovalo nějak
takto (už nikdy bys nemusel na repository přidávat žádnou
findByNěco() metodu):
class SomethingSpecial implements IQuery
{
public function createQuery(IMapper $mapper)
{
return array('SELECT * FROM %n', 'table', ' atd...');
}
}Tak tohle je ve stručnosti :-) moje představa o query objektech.
před 6 lety
- Tharos
- Člen | 1042
@llook: Moc díky, že sis našel čas a takhle vyčerpávajícím způsobem to popsal. Je to velmi inspirativní.
Celé mi to připadá jako hezký přístup a návrhově velmi čistý (existuje jasně dané API). Co mě k tomu napadá a co obojí rozvedu:
1. Nebylo by ještě praktičtější, kdyby existoval konkrétní Query Object pro entitu namísto pro repositář?
Tím by bylo umožněné použít takový Query Object i při traverzování mezi entitami. Na traverzování by šlo navěsit filtr, který by právě Query Object přijímal a aplikoval. No a do téhle aktivity repositář v Lean Mapperu nijak nevstupuje.
2. Nebylo by praktičtější překládat stav Query Objectu do volání fluent namísto do SQL?
Souvisí to částečně s bodem 1. Nepřišlo by se tak
o nic z dotazu, který už Lean Mapper předpřipravil. Pak by muselo
existovat spíše nějaké
QueryObject::apply(Fluent $statement).
Nejsem si zkrátka jist, zda je striktní překlad Query Objectu do SQL vždy nejvýhodnější – minimálně v kontextu Lean Mapperu.
před 6 lety
- llook
- Člen | 412
- Query není na repository nijak závislé.
- Může to vracet cokoli, s čím si poradí
DibiConnection::query(), což Fluent splňuje.
Já moc velký příznivec DibiFluent nejsem, radši píšu SQL přímo. Složitější dotazy píšu v Database Console, kde je hned vyzkouším a odladím. Přepisovat je pak z SQL do DibiFluent je práce navíc.
Napadá mě, že by query objekt kromě mapperu dostával ještě ten základní DibiFluent. Tím by se trochu omezily možnosti query objektů, ale je fakt, že většinu případů užití by to zjednodušilo. Nějaké konflikty při kombinaci více query nebo filtrů dohromady (ambiguous column apod.) by snad nastávaly málokdy:
interface IQuery
{
function createQuery(DibiFluent $baseQuery, Mapper $mapper);
}Ale co s těmi případy, kdy si fakt chci celý dotaz napsat ručně?
Takový query objekt by mohl ignorovat parametr $baseQuery, ale to
by bylo dost matoucí. Nebo by místo názvu tabulky mohl použít poddotaz
('FROM (%sql) t', $baseQuery), to je zase trochu prasácký.
Ještě nad tím zkusím popřemýšlet.