Oznámení
před 6 lety

- Tharos
- Člen | 1042
Ahoj,
po troše bilancování jsem se nakonec rozhodl uvolnit ORM nad dibi, které jsem nedávno sepsal (nyní je ve stable verzi 1.3.0).
Objektově relační mapování a doménový model jsou mému srdci blízké záležitosti, ale z těch pár existujících kvalitních ORM knihoven pro PHP jsem si prostě nevybral. A tak jsem se nakonec přidal k davu pošetilců a napsal si svou vlastní…
www.leanmapper.com
Co o něm zde ve stručnosti říct takovému Nette uživateli…
- Je postavené nad dibi a snaží se být nejenom praktickým nástrojem, ale také maximálně spolehlivým. Jsem přesvědčen, že dibi je pro takové ORM ta správná odladěná konzervativní knihovna.
- Je podrobně zdokumentované. Předsevzal jsem si, že nevypustím do světa bídně zdokumentovanou knihovnu. Asi naposledy v životě – netušil jsem, jaká je to piplačka něco poctivě zdokumentovat.
- Nemá závislost na Nette, takže je ho možné použít v podstatě kdekoliv (kde je PHP 5.3). Jedinou jeho závislostí je dibi.
- Dlouho jsem používal NotORM a líbí se mi jeho hlavní myšlenka (efektivní dotazy díky stahování souvisejících záznamů pro celý výsledek). Celý tento „NotORM princip“ jsem tedy do Lean Mapperu naimplementoval. Při práci s ním tedy typicky Lean Mapper položí databázi úplně stejné dotazy, jaké by položil NotORM (anebo Nette\Database).
- Způsob získávání souvisejících entit je inspirován YetORMem. Chtěl bych tady Petrovi ještě jednou poděkovat za jeho knihovnu a za inspiraci, jak lze k téhle záležitosti přistoupit. Díky!
Tak kéž někomu bude k užitku.
No a samozřejmě maximálně vítám konstruktivní ohlasy, náměty, bug reporty… zkrátka vše, co by mohlo nasměrovat vývoj Lean Mapperu v řadě 1.4.x. :)
Editoval Tharos (25. 10. 2013 21:09)
před 6 lety

- Filip Procházka
- Moderator | 4693
Dobře ty! Krásná dokumentace, zrovna si ji pročítám. Chtěl jsem začít testy, ale žádné jsem nenašel :P
před 6 lety

- hrach
- Člen | 1810
Prosim o ukazku jak se pomoci te obalky nad dibi udela toto:
AuthorRepository vrati vsechny autory, kteri spatne oznacili svoje knihy tagy, tzn. vrati takove autory, jejichz 1..n knih ma mene nez 2 tagy. Díky :)
Ad dokumentace, ano ano, je to piplacka, je pekne ze sis pohral :) jeste jdu mkrnout na kod knihovny.
před 6 lety
- Tharos
- Člen | 1042
Filip Procházka napsal(a):
Chtěl jsem začít testy, ale žádné jsem nenašel
Jsou, ale původní jsou v PHPUnitu a další chci psát už v Nette Testeru, takže ty staré aktuálně přepisuji. Mám je rozdělané v jedné lokální branchi u sebe a velmi brzy je do hlavního repa taky pushnu. Nechtěl jsem vydání odkládat ještě do té doby, než ty testy zmigruju. Už tak jsem měl plné zuby té docky… :)
před 6 lety
- Tharos
- Člen | 1042
@hrach: To je víceméně taková písemka z SQL :).
<?php
namespace Model\Repository;
class AuthorRepository extends \LeanMapper\Repository
{
public function findAllIncorrect()
{
return $this->createEntities(
$this->connection->select(......) // zde takové autory vytáhneme normálně pomocí SQL
);
}
}
?>Mám teď možnost být u PC asi už jen dvě minuty, ale večer ten SQL dotaz doplním.
O něco zajímavější by bylo, kdybychom chtěli takovouto kolekci špatných autorů získat třeba z nějaké jiné entity (zkrátka aby existovalo něco jako $institute->incorrectAuthors). I toho je v Lean Mapperu jednoduché docílit – slouží k tomu filtry, které jako jediné teď ještě nejsou zdokumentované…
Večer sem asi napíšu ukázku i tohohle, protože si myslím, že to je v Lean Mapperu mocná věc… Pomocí těch filtrů se dá nejen limitovat a řadit výsledek, ale umožňují například namapovat entitu rozprostřenou přes více tabulek, provádět dost specifické restrikce (třeba takovou, o jaké jsi psal) atp.
Dokumentace k tomu zatím není z toho důvodu, že zatím teprve ladím, za jaký konec dokumentaci téhle části uchopit a nejlépe vše vysvětlit.
Editoval Tharos (4. 6. 2013 23:19)
před 6 lety
- Tharos
- Člen | 1042
@hrach: Takže, jak jsem slíbil, ještě se ke Tvému dotazu trochu rozepíšu. :)
Nejpřímočařejší řešení Tvého problému je následující metoda v repositáři:
public function findAllIncorrect()
{
return $this->createEntities(
$this->connection->select('[author.*]')->from('author')
->join('book')->on('[book.author_id] = [author.id]')
->join('book_tag')->on('[book_tag.book_id] = [book.id]')
->groupBy('[author.id]')
->having('COUNT(DISTINCT [book_tag.tag_id]) < 2')
->fetchAll()
);
}Jak jsem psal, je to v podstatě jenom takové cvičení z SQL. Lean Mapper prostě potřebuje relaci, ze které vyrobí patřičné entity.
Nicméně, jestli dovolíš, pokusím se Tvého dotazu využít k tomu, abych demonstroval něco dalšího, co knihovna umožňuje.
Problém
Pro každou knihu chceme umět získat autora, ale řešíme teď pouze ty,
kteří špatně označili své knihy. Ostatní autory ignorujeme. Jinak
řečeno chceme, aby existovalo něco jako položka
$book->incorrectAuthor, která bude obsahovat buďto null (pokud
autor knihy při označování svých publikací nechyboval), anebo právě toho
„nedbalého“ autora.
Vím, že je to trochu kostrbaté zadání a rozhodně by se dalo vymyslet lepší, ale snažím se recyklovat, co už máme. :–P
Řešení #1
Do entity Book můžeme přidat následující metodu:
const DEFAULT_INCORRECT_THRESHOLD = 2;
public function getIncorrectAuthor($threshold = null)
{
if ($threshold === null) {
$threshold = self::DEFAULT_INCORRECT_THRESHOLD;
}
$referencedRow = $this->row->referenced('author', function ($statement) use ($threshold) {
$statement->select('[author.id]')->join('book')->on('[book.author_id] = [author.id]')
->join('book_tag')->on('[book_tag.book_id] = [book.id]')
->groupBy('[author.id]')
->having('COUNT(DISTINCT [book_tag.tag_id]) < %i', $threshold);
});
return $referencedRow === null ? null : new Author($referencedRow);
}Poté můžeme u knihy přistoupit k položce
$book->incorrectAuthor. Dokonce můžeme i doladit hranici, od
kdy jsou autoři považováni za nedbalé:
$book->getIncorrectAuthor(4).
Řešení #2
No a teď něco zajímavějšího. :) Pokud bychom chtěli mít možnost načíst nedbalé autory jak z repositáře tak i z entity Book, zjistíme, že se nám v aplikaci opakuje stejná logika na více místech. Vyzkoušená cesta do pekel.
Řešením je definice filtru, který se poté použije jak v repositáři, tak i v entitě. Filtry lze použít všude tam, kde se Lean Mapper na něco ptá do databáze, a s jejich pomocí lze libovolně upravit připravený DibiFluent statement těsně před tím, než jej Lean Mapper vykoná. Je to nesmírně užitečný koncept, který umožní výsledek limitovat, seřadit, udělit na něj další restrikce, někde něco přijoinovat…
<?php
namespace Model\Filter;
use DibiFluent;
/**
* @author Vojtěch Kohout
*/
class AuthorFilter
{
const DEFAULT_INCORRECT_THRESHOLD = 2;
public static function filterIncorrect($statement, $threshold = null)
{
if ($threshold === null) {
$threshold = self::DEFAULT_INCORRECT_THRESHOLD;
}
$statement->select('[author.id]')->join('book')->on('[book.author_id] = [author.id]')
->join('book_tag')->on('[book_tag.book_id] = [book.id]')
->groupBy('[author.id]')
->having('COUNT(DISTINCT [book_tag.tag_id]) < %i', $threshold);
}
}
?>No a s takovýmto filtrem pak metodu findAllIncorrect
v repositáři můžeme zjednodušit na:
public function findAllIncorrect($threshold = null)
{
$statement = $this->connection->select('[author.*]')->from('author');
AuthorFilter::filterIncorrect($statement, $threshold);
return $this->createEntities($statement->fetchAll());
}A definice entity je pak úplně triviální (prostě si vystačíme s anotacemi):
<?php
namespace Model\Entity;
use Model\Filter\AuthorFilter;
use DibiDateTime;
/**
* @property int $id
* @property Author $author m:hasOne
* @property Author|null $incorrectAuthor m:hasOne m:filter(AuthorFilter::filterIncorrect)
* @property string $title
* @property string|null $description
* @property DibiDateTime $published
* @property bool $active
*/
class Book extends \LeanMapper\Entity
{
}
?>Všechna následující volání jsou pak použitelná a dělají to, co se od nich očekává:
$incorrectAuthors = $authorRepository->findAllIncorrect();
$incorrectAuthors = $authorRepository->findAllIncorrect(4);
$book = $bookRepository->find(1);
$incorrectAuthor = $book->incorrectAuthor;
$incorrectAuthor = $book->getIncorrectAuthor(4);No… Tak snad jsem to popsal srozumitelně. Jak už jsem zmínil, filtry
ještě musím zdokumentovat. Lze jich například i v anotacích aplikovat
více
současně! m:filter(AuthorFilter::filterIncorrect,OrderFilter::orderBy,LimitFilter::limitAndOffset)
Doplnění: Mimochodem – filtr by ani nemusel být statický. V ukázce je statický jen proto, aby se nám na něj pohodlně odkazovalo z anotace. Nic nebrání tomu mít filtr zaregistrovaný jako službu a předávat si jej na místo určení podle potřeby. Jen je s tím více psaní (jak už to u DI bývá).
Editoval Tharos (4. 6. 2013 23:03)
před 6 lety

- Etch
- Člen | 404
V Lean Mapperu strikně platí, že entity neumějí samy sebe persistovat – potřebují k tomu repositáře. V následující ukázce se uloží pozměněný název knihy, ale už ne pozměněný název autora:
$book = $bookRepository->find(1); $book->name = 'New book name'; $author = $book->author; $author->name = 'New author name'; $bookRepository->persist($author); // ???
Nemělo by tam být spíše $bookRepository->persist($book);
nebo si mám poposednout a přečíst si to celé ještě jednou?? :)
před 6 lety
- Tharos
- Člen | 1042
@Etch: Poposednout bych si měl při psaní dokumentace občas spíš já :). Samozřejmě jsem tam měl „překlep“ (dá-li se tohle ještě za překlep označit). Fixed. Díky za report!
před 6 lety
- hrach
- Člen | 1810
Diky, samozrejme neslo presne o ten kod, jen spis o ukazku prace se slozitejsimi vazbami.
před 6 lety

- Jan Tvrdík
- Nette guru | 2550
@Tharos: Vypadá do pěkně, máš velké plus za nepoužití Nette\Database :-)
Plánuješ přidat nějakou podporu pro enum?
před 6 lety

- Filip111
- Člen | 244
Pěkný – nikdy jsem si pořádně nezvykl na NDB, takže ORM nad dibi je fajn.
Mám pár otázek:
- Lze pomocí anotací nadefinovat jiný název DB tabulky nebo sloupce?
Např. abch měl entitu OrderDetail ale db tabulku order_detail + analogicky
pro sloupce, abych mohl mít sloupec name_first ale vlastnost entity
NameFirst?
(zatím jsem si ničeho podobnýho v kódu ani dokumentaci nevšiml a dost by
se mi to hodilo)
- Už dlouho se snažím vyřešit problém s výcejazyčnými tabulkami, moje představa je mít dvě tabulky, např.
pages (id, status, date_created)
pages_translation (page_id, lang, text)
ale mít jen jednu entitu se kterou budu pracovat, tedy Pages s prvky id,
status, date_created, text (případně lang).
Dalo by se toho docílit pomocí filtru? Pro čtení asi ano, ale potřeboval bych to i pro zápis s tím, že nastavení aktuálního jazyka by bylo nějak předáno filtru/entitě nebo by bylo rovnou součástí entity.
(s tou vícejazyčností se peru už hodně dlouho a zatím jsem to nedokázal uspokojivě vyřešit – Doctrine se mi líbí, ale Gedmo mi nesedí a spravovat vícejazyčný entity jen pomocí vazem je neskutečná práce. Ani nemůžu data jednoduše předat do formuláře).
Díky.
před 6 lety
- Tharos
- Člen | 1042
@Jan Tvrdík: Díky za kladné zhodnocení. :)
Podporu pro enum přidám rád. Přiznám se, že sám typ enum v databázích příliš nepoužívám, a tak si chci dobře rozmyslet API a pak bych sem stejně asi ještě dal nějaké RFC… Píšu si to do roadmap do řady 1.4.
Rád bych v horizontu několika dní dal roadmap na web (a spolu s ním i changelog). Do verze 1.4 mám mimo jiné na programu usnadnění persistence jednoduchých M:N vazeb, aby fungovalo následující:
$book->addTag($tag1);
$book->removeTag($tag2);
$bookRepository->persist($book);Samozřejmě s tím, aby se tagy insertovaly a mazaly inteligentně (tj. nikoliv, aby se vymazaly všechny staré a do db nasypaly nové a podobné ošklivosti…).
Až bude ten roadmap připravený, dám sem avízo.
@Filip111: Oba problémy by měly být už ve verzi 1.3 řešitelné. Sám si ale pohraji s optimálním řešením, tj. takovým, aby ses neupsal. To je asi největší záludnost… Nedodržení konvencí v Lean Mapperu v první řadě znamená psaní navíc a často má více řešení.
Stay tunned, rád si s tím pohraju a pošlu sem resumé. :)
před 6 lety
- Tharos
- Člen | 1042
@uestla, @Filip111: Velmi snadno se
přetíží názvy tabulek a názvy sloupců reprezentující vazby. To je také
IMHO nejčastější porušení konvencí, protože v téhle věci občas
konvence dodržet prostě nelze (třeba u $book->author a
$book->reviewer vedoucích na stejnou entitu).
Trochu pracnější je přemapování sloupců (bookTitle → book_title), ale je to řešitelné. Platí, že sem o tom pošlu post.
před 6 lety
- Filip111
- Člen | 244
@uestla: četl jsem – repository jsem asi
přeskočil, řešení jsem čekal v entitě pomocí anotace
Tharos: díky, těším se
před 6 lety

- besanek
- Člen | 128
Super! Moc se mi líbí. Už se těším až si ho zkusím někam nasadit. :)
před 6 lety
- Tharos
- Člen | 1042
@Filip111: Tak snad Tě potěším – oba Tvé problémy mají v Lean Mapperu vcelku přímočaré řešení. :)
Aby sis nemusel překopírovávat kódy tady z fóra, připravil jsem Ti balíček s řešením ke stažení (používá SQLite databázi, která je jeho součástí, takže fakt stačí rozbalit a spustit).
Dám sem jen schéma databáze, ke kterému se můj text tady bude vztahovat:
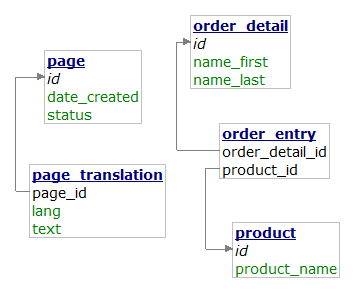
Na úvod už snad jen upozorním, že jsem pro usnadnění řešení
prvního problému kód Lean Mapperu lehce rozšířil, takže co teď
budu psát platí pro poslední commit v develop branchi na GitHubu (přičemž z této
branche se zanedlouho vyklube verze 1.4.0).
Definice jiného názvu tabulky nebo sloupce
Jak jsem již naznačil, v Lean Mapperu 1.3.0 lze snadno upravit názvy sloupců a tabulek souvisejících s vazbami mezi entitami (takové ty m:hasMany(sloupce a tabulky) příznaky). Ty se definují v entitách. Upozorňuji, že entita neví, do jaké tabulky ona sama patří a je to v pořádku – na nic to nepotřebuje vědět. Lean Mapper vychází z Data mapper vzoru a v něm entity o žádných tabulkách vůbec nic neví. Jediné odchýlení od Data mapper vzoru spočívá v tom, že entita si sama dokáže načíst související entity. A k tomu potřebuje vědět, kam se pro ně do databáze podívat.
Tabulku a třídu entity lze doladit v anotaci nad repositářem, protože to, do jaké tabulky pro entitu sáhnout a co za entitu vlastně vytvořit, je zodpovědnost repositáře. To jen tak na úvod a jako reakce na: repository jsem asi přeskočil, řešení jsem čekal v entitě pomocí anotace.
Nicméně pro namapování ostatních sloupců jsem přidal podporu v
develop větvi. Ono by to ve verzi 1.3.0 šlo, ale položky by se
musely definovat skrze metody a s tím je o řád více psaní…
Tvé zadání (které jsem si dovolil ještě trochu rozšířit, viz dále) lze vyřešit následovně:
<?php
namespace Model\Entity;
/**
* @property int $id
* @property Product[] $products m:hasMany(order_detail_id:order_entry:product_id)
* @property string $firstName (name_first)
* @property string $lastName (name_last)
*/
class OrderDetail extends \LeanMapper\Entity
{
}
/**
* @property int $id
* @property string $productName (product_name)
*/
class Product extends \LeanMapper\Entity
{
}
?><?php
namespace Model\Repository;
/**
* @table order_detail
*/
class OrderDetailRepository extends Repository
{
}
?>Domyslel jsem si ještě entitu Product a vazební tabulku (schválně
pojmenované dost nekonvenčně), abych to trochu okořenil a ukázal,
jak se mapují sloupce v položkách reprezentujících vazbu. Abstraktní
třída Model\Repository odpovídá té v quick startu.
Pak lze provádět následující operace:
$orderDetails = $orderDetailRepository->findAll();
foreach ($orderDetails as $orderDetail) {
write('Jméno: ' . $orderDetail->firstName);
write('Příjení: ' . $orderDetail->lastName);
write('Objednané položky:');
foreach ($orderDetail->products as $product) {
write($product->productName, 3);
}
separate();
}Řešení tabulky s překlady
Vše, co potřebuješ, řeší následující třídy:
<?php
namespace Model\Entity;
/**
* @property int $id
* @property string $dateCreated (date_created)
* @property string $status
* @property string $lang
* @property string $text
*/
class Page extends \LeanMapper\Entity
{
}
?><?php
namespace Model\Filter;
use DibiFluent;
class PageFilter
{
public static function joinTranslation(DibiFluent $statement, $lang)
{
$statement->leftJoin('page_translation')
->on('[page_translation.page_id] = [page.id]')
->where('[lang] = %s', $lang);
}
}
?>A trochu upovídanější (ale principiálně jednoduché) repository:
<?php
namespace Model\Repository;
use LeanMapper\Entity;
use Model\Filter\PageFilter;
class PageRepository extends \LeanMapper\Repository
{
public function find($id, $lang)
{
$statement = $this->connection->select('*')
->from($this->getTable())
->where('id = %i', $id);
PageFilter::joinTranslation($statement, $lang);
$row = $statement->fetch();
if ($row === false) {
throw new \Exception('Page was not found.');
}
return $this->createEntity($row);
}
public function persist(Entity $entity) // $entity instanceof Page
{
if ($entity->isModified()) {
$values = $entity->getModifiedData();
if ($entity->isDetached()) {
$this->connection->insert(
$this->getTable(),
array_intersect_key($values, array_flip(array('id', 'date_created', 'status')))
)->execute();
$id = $this->connection->getInsertId();
$this->connection->insert(
'page_translation',
array_intersect_key($values, array_flip(array('lang', 'text'))) + array('page_id' => $id)
)->execute();
$entity->markAsCreated($id, $this->getTable(), $this->connection);
return $id;
} else {
$pageTableValues = array_intersect_key($values, array_flip(array('date_created', 'status')));
if (!empty($pageTableValues)) {
$this->connection->update($this->getTable(), $pageTableValues)
->where('[id] = %i', $entity->id)
->execute();
}
$pageTranslationTableValues = array_intersect_key($values, array_flip(array('lang', 'text')));
if (!empty($pageTranslationTableValues)) {
$this->connection->update('page_translation', $pageTranslationTableValues)
->where('[page_id] = %i AND [lang] = %s', $entity->id, $entity->lang)
->execute();
}
$entity->markAsUpdated();
}
}
}
}
?>Všimni si, že až na repositář, který prostě musí rozhodnout co kam sypat a odkud co načítat, je vše triviální.
Třídy pak můžeš používat následovně:
$page = $pageRepository->find(1, 'cs');
write($page->id);
write($page->lang);
write($page->text);
separate();
$page = $pageRepository->find(1, 'en');
write($page->id);
write($page->lang);
write($page->text);V ukázce, kterou máš ode mě v archivu (i s daty), dostaneš výpis:
1
cs
český text úvodní stránky
-----
1
en
english content of homepageNo a samozřejmě funguje i persistence:
$page = new Page;
$page->dateCreated = '2012-01-01 12:00:00';
$page->status = 'created';
$page->lang = 'sk';
$page->text = 'slovenský obsah stránky';
$pageRepository->persist($page);
$page->text = 'upravený slovenský obsah stránky';
$pageRepository->persist($page);
write($page->id);
write($page->text); // vypíše "upravený slovenský obsah stránky"
separate();
$page = $pageRepository->find($page->id, 'sk');
write($page->id);
write($page->text); // vypíše "upravený slovenský obsah stránky"K ideálnímu porozumění tomu, co to vypíše, je vhodné mít vedle i výchozí stav databáze, takže určitě se na to podívej v tom archivu.
Tak doufám, že jsem správně pochopil zadání a má řešení jsou trefná. Upřímně řečeno, v tom mapování entit rozlezlých přes více tabulek mi přijde Lean Mapper jako úžasně silný nástroj.
Jinak všimni si, že ten vyrobený filtr by šel recyklovat i jinde v aplikaci. Na stránky by například mohli odkazovat autoři:
<?php
namespace Model\Entity;
use Model\Filter\PageFilter;
/**
* @property int $id
* @property Page[] $pages m:hasMany m:filter(PageFilter::joinTranslation)
* @property string $name
*/
class Author extends \LeanMapper\Entity
{
}
?>A používalo by se to pak následovně:
$author = $authorRepository->find(12);
foreach ($author->getPages('cs') as $page) {
write($page->id);
write($page->text);
}Editoval Tharos (4. 6. 2013 22:47)
před 6 lety
- Filip111
- Člen | 244
@Tharos:
páni, takhle vyčerpávající odpověď jsem fakt nečekal!
Stáhnul jsem si zdrojáky a vyzkoušel. Samotná práce s entitou je supr,
definice entity už je taky supr (když můžu definovat vlastní název sloupce
v DB).
Jak zmiňuješ, tak definice repository u vícejazyčné entity je trochu
složitější – s tím zkusím ještě něco udělat. Bylo by fajn, kdyby
se mi to povedlo nějak zobecnit, abych takové repository mohl podědit a
nepřidělávat si práci s vyjmenováním všech sloupců (u 100 entit už
je to docela otročina, navíc by to bylo další místo na údržbu
v budoucnu).
V metodě PageRepository->persist() je jen malé opomenutí stavu, kdy
entita již existuje, ale aktuální jazyková varianta nikoliv. Takže ještě
rozhodování zda bude insert/update nad tabulkou překladů. Tzn. ještě
trochu víc psaní v repository a další důvod, proč to zobecnit.
Taky chci do tohoto Repository zabudovat nějaký fallback v případě
nenalezení požadovaného jazyka, ale to asi nebude problém.
Zkusím to v praxi a pak se uvidí.
Mám dotaz ohledně 1:N vazby – v dokumentaci je jen ukázka se čtením,
zkoušel jsem ale přidávat například nový produkt do objednávky a stále
se nemohu dostat přes chybu:
Indirect modification of overloaded property Model\Entity\OrderDetail::$products has no effect
Zkoušel jsem:
$p = new Model\Entity\Product;
$p->productName = 'myProduct';
$orderDetail->products[] = $p;
// pripadne dplneni metody addProduct a $this->products[] = $p; v OrderDetail entite
// $orderDetail->addProduct($p);Na závěr díky, díky, díky.
před 6 lety

- bazo
- Člen | 625
skus
$products = $orderDetail->products;
$products[] = $p;
$orderDetail->products = $products;Editoval bazo (4. 6. 2013 15:12)
před 6 lety
- Tharos
- Člen | 1042
Tohle prozatím nefunguje. Přidat lepší podporu pro persistenci M:N vazeb plánuji ve verzi 1.4.0 (a spolu s podporou enumu to bude asi jedná nová featura). Už to mám víceméně rozmyšlené, takže by se to během několika dní mělo objevit v develop větvi…
Persistence těchto vazeb mi přijde jako snadno zkazitelná (z hlediska API i implementace), a tak bych rád postupoval dopředu opatrně. API bych nejprve řešil přes metody:
$order->addToProducts($product);
// $order->removeFromProducts($product);
$orderRepository->persist($order);Hezčí by bylo určitě $order->addProduct(...), ale u toho
je trochu problém se singulárem a plurálem – název položky je typicky
plurál ($order->products) zatímco ty metody by potřebovaly singulár
($order->addProduct()). Samozřejmě chci, aby ty metody využívaly __call a
nemusely se definovat ručně. Zatím mě tedy nenapadlo nic lepšího, než
addTo a removeFrom… Jsem otevřen jakýmkoliv nápadům. :)
A přidávání přes [] bych eventuálně doplnil jen jako syntactic suggar (+ jak řešit odebírání?).
V první implementaci bych neřešil následující:
- Nahrazení celé kolekce nějakou jinou
(
$order->products = array(...)). Tohle bych dovolil, až si budu skutečně jist, že to nebude způsobovat žádné skryté vedlejší problémy. - Persistence vazeb, kde vazební tabulka obsahuje nějaké doplňující
údaje (datum vzniku vazby atp.). Tohle lze uspokojivě řešit definicí entity
pro vazební tabulku a IMHO to je vhodné řešení (viz
borrowingv quick startu).
Jinak já osobně ve svých aplikacích nyní persistuji M:N vazby pomocí
speciálních metod v repositáři
($orderRepository->addProduct($order, $product)), což je
takový funkční workaround. Rozhodně ale nechci u tohohle dlouho
zůstat.
Editoval Tharos (4. 6. 2013 16:09)
před 6 lety
- Jan Tvrdík
- Nette guru | 2550
Tharos wrote: Jsem otevřen jakýmkoliv nápadům.
Jen pro inspiraci (pokud jsi to ještě neviděl) jak to řeší ORM od
PetrP – property $products není typu Product[] ale
typu Orm\ManyToMany (která je díky implementaci
IteratorAggregate iterovatelná) a na ní se pak volají metody
add($order), remove($order) a
has($order).
před 6 lety
- Tharos
- Člen | 1042
To je hezké řešení. Hned mě napadá i následující:
/**
* @property int $id
* @property Product[] $products m:hasMany
*/
class Order extends \LeanMapper\Entity
{
}
$order->products->add($product);
$order->products->remove($product);
$order->products->has($product);
$orderRepository->persist($order);Od typu Product[] u anotace bych nerad opustil, protože mu už
začínají dobře rozumět IDE a to je velké plus. Plus mu rozumí třeba
i ApiGen… Díky za inspiraci!
před 6 lety
- Jan Tvrdík
- Nette guru | 2550
@Tharos: Co se týče návrhu LeanMapperu tak mě zaujaly (přijdou divné) tři věci:
- Relace definované pomocí anotací na entitě se odkazují na tabulku v databázi místo na jiný repositář (který ví na kterou tabulku se mapuje).
- Chybějící identity map (částečně to spolu souvisí s předchozím bodem.)
LeanMapper\Repository::$defaultEntityNamespace– globální magie je zlo, pokud to někdo potřebuje, ať si přepíšegetEntityClassve svémBaseRepository
Editoval Jan Tvrdík (4. 6. 2013 18:10)
před 6 lety

- llook
- Člen | 412
Entity[] v anotaci je určitě správná myšlenka. PetrP/Orm
vyžaduje Orm\OneToMany nebo Orm\ManyToMany proto, že umožňuje použít
i jinou, než výchozí implementaci. Osobně mi to ale přijde docela zbytné
a pokud to už umožnit, tak spíš nějakou vyměnitelnou továrnou nebo
tak nějak.
Btw. jaktože tu ještě nikdo neprudí, že téma nesouvisí s Nette? :-)
před 6 lety
- Jan Tvrdík
- Nette guru | 2550
Ještě je tu možnost uvést oba typy zároveň, tj.
@property Product[]|\LeanMapper\ManyToMany $products. Vypadá to
škaredě, ale napovídat by to díky tomu mělo správně. Preferoval bych
současný kompaktní zápis, ale umožnil bych i uvést oba typy pro případ,
že někdo bude chtít funkční napovídání a časem to umožní i výměnu
implementace, bude-li to k něčemu potřeba.
Btw. jaktože tu ještě nikdo neprudí, že téma nesouvisí s Nette? :-)
Není pravda, web Lean Mapperu běží na Nette :) A hlavně moderátoři jsou rozumní.
před 6 lety
- Tharos
- Člen | 1042
@Jan Tvrdík: Díky za dobré připomínky.
Ad 1 + 2) Rozumím, co tím máš na mysli. Vážně zvažuji, že tímhle směrem nasměruji Lean Mapper v řadě 2.0. Ale bude to experiment, protože takové řešení má z mého pohledu své výhody, ale i nevýhody. Tak jako současné řešení má své výhody a nevýhody. :) Nechci jej nijak hájit, využívá jen prostě trochu jiné paradigma, než třeba taková dvojková Doktrína.
Vím, že zatažení repositářů do vazeb by mělo následující výhody:
- Vnitřní implementace by byla svým způsobem hezčí.
- Asi by se zmenšila potřeba používání filtrů na dvou místech (v repositářích a u anotací entity).
Ale bojím se následujících nevýhod:
- ORM nakyne. Přibude svým způsobem další vrstva a je otázka, jak si bude rozumět s NotORM stylem dotazů. Reálně pak bude asi potřeba Identity Map – všimni si, že knihovna se nyní bez ní v podstatě obejde (díky LeanMapper\Result, LeanMapper\Row a tomu, kde jsou skutečná data – instance entit jsou už jen obálky).
Každopádně to ale minimálně vyzkouším.
Ad 3) Jo, zde se dá bez statického členu opravdu žít. Ona by to mohla být klidně i jenom protected proměnná. Přece jenom přetěžovat metodu už je dost psaní… ;) Zvláště pak ne zrovna dvouřádkovou. Já se toho statického členu osobně neštítím, ale máš pravdu, že jeho zrušení by bylo „výchovnější“. Díky za tip.
@llook: Entity[] v anotacích bych se
vážně nerad vzdal. Napadlo mě pokusit se využít následujícího:
Entity[] IMHO neznamená vyloženě array instancí
Entity, to může mít přece klidně i význam kolekce s instancemi
Entity, nad kterou se dá iterovat. Napadlo mě, že by Lean Mapper tedy
používal tento způsob definice v anotaci, ale nevracel by pole, nýbrž
kolekci (s potřebným API a inteligencí).
Moderátorům děkuji, že mi tady tohle tolerují. :) Přiznávám, že inspirace uvařená zde je pro mě k nezaplacení.
Editoval Tharos (9. 6. 2013 0:36)
před 6 lety
- Etch
- Člen | 404
@Tharos:
Vím, že je to spíše filozofický problém, ale neměla by si metoda
persist a delete v repository kontrolovat, jestli
opravdu dostává Entitu, která jí náleží?? Něco třeba na způsob:
public function persist(Entity $entity)
{
$entityClass = $this->getEntityClass();
if(!($entity instanceof $entityClass)){
throw new \Exception('...');
}
if ($entity->isModified()) {
$values = $entity->getModifiedData();
if ($entity->isDetached()) {
$this->connection->insert($this->getTable(), $values)
->execute(); // dibi::IDENTIFIER would lead to exception when there is no column with AUTO_INCREMENT
$id = isset($values['id']) ? $values['id'] : $this->connection->getInsertId();
$entity->markAsCreated($id, $this->getTable(), $this->connection);
return $id;
} else {
$result = $this->connection->update($this->getTable(), $values)
->where('[id] = %i', $entity->id)
->execute();
$entity->markAsUpdated();
return $result;
}
}
}V současné implementaci totiž může klidně projít následující:
$magazineRepository = new \Model\Repository\MagazineRepository($connection);
$book = new \Model\Entity\Book();
$book->title = 'foo';
$magazineRepository->persist($book);Pokud entita Book nebude mít definovanou nějakou property,
kterou nemá entita Magazine, tak kód výše normálně projde a
entita Book bude uložena zcela jinam než by měla být.
U metody delete mi pak tato ‚vlastnost‘ přijde ještě
„nebezpečnější“:
$magazineRepository = new \Model\Repository\MagazineRepository($connection);
$bookRepository = new \Model\Repository\BookRepository($connection);
$book = $bookRepository->find(123);
$magazineRepository->delete($book);Místo upozornění, že se snažím repository nacpat špatnou entitu, to
bez milosti smaže časopis s příslušným ID entity Book.
Editoval Etch (8. 6. 2013 9:27)
před 6 lety
- Etch
- Člen | 404
@Tharos:
A už jen tak mimochodem bych se chtěl zeptat, jestli v budoucnu
plánuješ implementovat u entit anotaci @property-read, která by
ideálně takovou property automaticky vyřadila z persistence. Uvedu
i takovej kostrbatej příklad.
Mějme nějakou entitu Book:
namespace Model\Entity;
/**
* @property int $id
* @property string $name
* @property Rating[] $ratings m:belongsToMany
* @property Comment[] $comments m:belongsToMany
* @property Comment[] $commentsWithRatings m:belongsToMany m:filter(\Model\Expansion\Comment::withRatings)
*/
class Book extends \LeanMapper\Entity{
}a entitu Comment:
namespace Model\Entity;
/**
* @property int $id
* @property string $content
* @property User $user m:hasOne
* @property-read int|null $rating
*/
class Comment extends \LeanMapper\Entity{
}„filtr“ \Model\Expansion\Comment::withRatings dělá
v podstatě jen to, že při volání
$book->commentsWithRating;přidá do query subselect, který vytáhne hodnocení z jiné tabulky. Je to vlastně pouze pomocná property, která má usnadnit některé výpisy.
Toto samozřejmě funguje i bez anotace @property-read, ale má
tu neblahou vlastnost, že při použití klasické anotace
@property jí schroustá i
$repository->persist($entity).
Následující kód tedy logicky skončí chybou:
$commentRepository = new \Model\Repository\CommentRepository($connection);
$comment = $commentRepository->find(123);
$comment->content = 'foo';
$comment->rating = 2; // Pokud by se tento řádek vynechal, komentář uloží v pořádku.
$commentRepository->persist($comment);Nejedná se tedy o nic kritického, protože pokud někdo nezapomene, že se
vlastně jedná o „pseudo property“ a nepokusí se jí nastavit, tak vše
proběhne podle očekávání. Ovšem kdyby „existovala“ anotace
@property-read, která by byla automaticky vyřazena z persistence
+ při jejím setování se automaticky vyhodila výjimka, tak by to bylo
minimálně přehlednější.
Otázka tedy zní … plánuješ v budoucnu nějakou implementaci
@property-read?? Ptám se jen pro případ, že kdyby si
s něčím podobným v budoucnu nepočítal, tak aby jsme si podporu této
anotace dopsali sami.
Editoval Etch (8. 6. 2013 18:07)
před 6 lety
- Tharos
- Člen | 1042
@Etch: Díky za cenné připomínky.
Ad 1) Tohle je jasný logický bug. Opravu zahrnu do verze 1.3.1, kterou bych rád vypustil nějak začátkem příštího týdne…
Ad 2) Případ použití, který jsi uvedl, dává smysl a
rád tedy podporu pro @property-read zahrnu. Ono kdysi už pro něj
v Lean Mapperu podpora
byla, ale pak jsem chvíli měl entity read only (rozmýšlel jsem, za jaký
konec uchopit persistenci) a když jsem pak persistenci dodělával,
@property-read už jsem zpátky nezavedl.
Trochu záměrně, protože co jsem například u YetORM viděl,
@property-read svádí k použití u ID entity, což je ale
poměrně nešikovné. Minimálně to znemožňuje vložit záznam do tabulky,
která nemá nad ID auto increment.
Zahrnul bych to taky do verze 1.3.1, protože žádnou zpětnou nekompatibilitu to nezpůsobí.
Díky za inspiraci! :)
P.S.: Filtry umí pracovat s use statementy. Namísto:
/**
* @property Comment[] $commentsWithRatings m:belongsToMany m:filter(\Model\Expansion\Comment::withRatings)
*/můžeš mít IMHO o něco přehlednější:
use Model\Expansion\Comment;
/**
* @property Comment[] $commentsWithRatings m:belongsToMany m:filter(Comment::withRatings)
*/Editoval Tharos (8. 6. 2013 21:23)
před 6 lety

- uestla
- Backer | 743
ad property-read: Přemýšlel jsem, jak tohle
uchopit. Zatím jsem došel k řešení, že property-read jdou
nastavit jen jednou – ať už při mapování z databáze, nebo při
persistenci nově vytvořené entity a „refreshi“ AI hodnoty. Ač se to
může jevit jako proti pravidlům (nastavení property, která je jen ke
čtení), ale k lepšímu jsem nedospěl…
Omlouvám se za lehčí OT :)
před 6 lety
- Etch
- Člen | 404
@Tharos:
Ad 1) Tohle je jasný logický bug.
Po té, co jsem před nějakou dobou otevřel jednu třídu, jejíž
otvírání mi na 20 vteřin zaseklo NetBeans abych posléze zjistil, že má
47 metod, její délka je 3243 (slovy
třitisícedvěstěčtyřicettři) řádků, že type hinting autor zřejmě
považoval za nadbytečné psaní, method a property visibility zřejmě také
(= všechno public [ poravdě property tam existovala jenom jedna a třída
jí používala úplně na všechno ]), řádky dlouhé běžně
350 znaků, $GLOBALS bylo na každém pátém řádku, atd atd,
už téměř všechno považuji za filozofický problém. :D
Filtry umí pracovat s use statementy.
Hezké. Dobré vědět. Ono já si zatím s těma filtrama jen tak hraji, protože vzhledem k tomu, že k filtrům ještě nemáš dopsanou dokumentaci a já jsem logicky líný nějak hlouběji zkoumat zdrojáky, tak se do „větších akcí“ s filtry radši nepouštím. :D
Editoval Etch (8. 6. 2013 22:52)
před 6 lety
- Tharos
- Člen | 1042
@uestla: Klíčové jsou podle mě ty případy
užití. Ve Tvém vlákně o YetORM byla anotace @property-read
mám dojem hned několikrát použita u ID entity. Mně to na první pohled
přišlo rozumné, ale postupem času mi to čím dál více přišlo jako
zbytečné házení klacků pod nohy. Aneb proč by nemělo jít ID nastavit?
Update ID dobře proklíčovanou databázi nerozhodí a pokud to někdo chce (a
potřebuje – pokud například tabulka nemá auto increment), budiž.
Díky tomuhle mi nakonec přišlo @property-read zbytečné a
z Lean Mapperu jsem ho vyhodil.
Teď ale padnul další příklad užití, a to „dopočtené“ položky,
které nemá smysl nijak nastavovat. Tam se IMHO @property-read
velmi dobře hodí.
Asi bych teď zkusil revertnout to chování, které už jsem měl naimplementované … V něm prostě nebude možné nad takovou položkou zavolat magický setter. Inicializovat tu hodnotu ale půjde. Ono to bude chování, když nad tím tak přemýšlím, asi úplně identické s tím, co popisuješ… :)
Editoval Tharos (9. 6. 2013 0:40)
před 6 lety
- Tharos
- Člen | 1042
Mám taková dvě RFC k API…
Usnadnění persistence jednoduchých M:N vazeb
Jak moc praktické by vám přišlo následující API?
<?php
/**
* @property int $id
* @property Tag[] $tags m:hasMany
* @property string $name
*/
class Book extends LeanMapper\Entity
{
}
/**
* @property int $id
* @property string $name
*/
class Tag extends LeanMapper\Entity
{
}
//////////
$book = $bookRepository->find(1);
$tag = $tagRepository->find(1);
// Nejstručnější (preferovaná) varianta:
$book->tags[] = $tag; // přidání
unset($book->tags[$tag]); // odebrání
// Upovídanější varianta
$book->tags->add($tag); // přidání
$book->tags->remove($tag); // odebrání
// Fungovalo by samozřejmě i následující:
$tags = $book->tags;
$tags[] = $tag;
unset($tags[$tag]);
$tags->add($tag);
$tags->remove($tag);
// A IMHO by bylo praktické mít podporu i pro:
$tagId = 1;
$book->tags[] = $tagId; // přidání
unset($book->tags[$tagId]); // odebrání
$book->tags->add($tagId); // přidání
$book->tags->remove($tagId); // odebrání
$tags = $book->tags;
$tags[] = $tagId;
unset($tags[$tagId]);
$tags->add($tagId);
$tags->remove($tagId);
?>Když už by se zavedlo tohle, co pak třeba umožnit i následující?
$tag = $book->tags[1];Tohle by ale zůstala zapovězená činnost:
$book->tags[1] = $tag;Dává smysl proč? Nebo je to neintuitivní/magické?
Samozřejmě by pak po takovýchto operacích šlo jednoduše zavolat:
$bookRepository->persist($book); // vše se uložíVýčtový typ
Napadlo mě zavést nový příznak (m:match), který by mohl obsahovat regulární výraz, který musí hodnota položky matchnout. Samozřejmě by šel použít pouze u non-object & non-array typů. Pomocí jej by šel výčet pohodlně vyjádřit a navíc by měl ještě širší užití.
<?php
/**
* @property int $id
* @property string $status m:match(#^(active|inactive|deleted)$#)
* @property int $count m:match(#^[1-5]$#)
*/
class Book extends LeanMapper\Entity
{
}
?>Přišlo by vám to praktické?
Předem díky za reakce. :)
Edit: Opraven název příznaku m:match…
Editoval Tharos (10. 6. 2013 9:23)
před 6 lety
- Filip111
- Člen | 244
Za mě add a remove +1
Jak celé entity, tak id. Nevím, sice jestli je to v pořádku z pohledu
návrhu, ale v praxi se mi už kolikrát hodilo přiřazovat oboje.
m:match – jaký to bude mít v praxi význam? Dovedl bych si představit využít anotace k automatickému vygenerování formuláře včetně validace.
před 6 lety
- besanek
- Člen | 128
+1.
Jen bych dodal ještě podporu pro zjištění, jestli kolekce daný prvek již obsahuje.
Např.
isset($tags[$tag]);
$tags->has($tag);
isset($tags[$tagId]);
$tags->has($tagId);před 6 lety
- Tharos
- Člen | 1042
Bezva, naimplementuji to tedy tak, jak je to zde nadhozené.
@besanek: Dobrý nápad, volat isset() určitě umožním.
@Filip111: Mít možnost předat pouze ID je prostě praktické… Mám-li formulář s nějakým multiselectem, typicky z něj dostanu ID vybraných tagů a mně přijde zbytečné načítat cokoliv z databáze, když už vše potřebné znám… Každopádně je to ale jenom takový syntaktický cukr, „správnější“ je samozřejmě pracovat s celými entitami.
m:match má následující praktické dopady:
$book->status = 'active'; // OK
$book->status = Book::STATE_ACTIVE; // Book::STATE_ACTIVE === 'active' --> OK
$book->status = 'disabled'; // Vyhodí výjimku
$book->count = 1; // OK
$book->count = 6; // Vyhodí výjimkuFunguje to tak, že se prostě při přístupu k položce (čtení i zápisu) kontroluje, zda hodnotu daný regulární výraz matchne. Dá se to využít například pro zmíněný výčtový typ, ale nejen pro něj.
Generovat položky formuláře z anotací je velmi zajímavá myšlenka. :)
V instanci LeanMapper\Reflection\Property by mělo být dostupné
skoro vše potřebné.
před 6 lety
- Tharos
- Člen | 1042
Ahoj,
vydal jsem verzi 1.3.1 a při té příležitosti jsem také umístil na web changelog a roadmap.
Ve verzi 1.3.1 byly opraveny všechny známé chyby a nově přidané funkce nezpůsobují žádný BC break.
Jak je patrné z roadmapy, většina novinek, které plánuji do verze 1.4.0, je již hotová v develop větvi na GitHubu. Do verze 1.3.1 jsem je ale nezahrnoval, protože obsahují drobné BC breaky. V každém případě verzi 1.4.0 bych chtěl vydat velice brzy. A pak bych se zaměřil na dopsání dokumentace, nějakých pokročilejších ukázek a taky testů…
Editoval Tharos (10. 6. 2013 19:47)
před 6 lety
- Jan Tvrdík
- Nette guru | 2550
@Tharos: Implementace výčtového typu se mi nelíbí, protože ten enum musíš v té entitě definovat na dvou místech (konstanty pro používání v aplikaci a pak znova v m:match). Co třeba:
/**
* @property int $id
* @property string $status m:enum(self::STATUS_*)
*/
class Book extends LeanMapper\Entity
{
const STATUS_ACTIVE = 'active';
const STATUS_INACTIVE = 'inactive';
const STATUS_DELETED = 'deleted';
}před 6 lety
- Tharos
- Člen | 1042
@Jan Tvrdík: Hezký, vymyslel jsi asi po všech směrech lepší řešení. :)
m:match bych do verze 1.4.0 stejně naimplementoval, vidím v něm velký potenciál, ale na výčet bude Tebou navržený příznak m:enum rozhodně lepší. Takže to píšu do roadmapy.
Za tohle navedení vážně díky.
před 6 lety
- Jan Tvrdík
- Nette guru | 2550
Ještě doplním, že by ideálně měly fungovat i následující zápisy
m:enum(self::STATUS_ACTIVE, self::STATUS_INACTIVE, self::STATUS_DELETED)
m:enum(Book::STATUS_ACTIVE, Book::STATUS_INACTIVE, Book::STATUS_DELETED)
m:enum(active, inactive, deleted) nebo m:enum('active', 'inactive', 'deleted')před 6 lety
- Tharos
- Člen | 1042
Budu to brát postupně. :) Právě jsem pushnul na GitHub podporu pro zápis, který jsi zmínil zde. Jak to v praxi funguje je vidět v testech.
Pokusil jsem se pohrát si s tím, aby to rozumělo výrazům
self::, static::, parent::,
SomeClass::… a aby to respektovalo
i use statement (když už ten parser mám, že…). Věřím, že
chování je teď intuitivní.
Všechny Tebou navržené další verze mi přijdou užitečné. Jen bych je ale asi neimplementoval vzápětí, protože teď mi třeba přijde aktuálnější ta podpora správy a persistence M:N vazeb (minimálně já už bych jí docela ocenil :–P).
Časem ale rád naimplementuji i ty další Tebou navržené varianty, nebude to nic složitého.
před 6 lety

- Šaman
- Člen | 2275
Ahoj, dá se nějak jednoduše pracovat s počitadly? Myslím tím takovou tabulku, která obsahuje jen ID a popis. Například tabulka ‚sex‘, obsahujízí dva řádky (1, ‚muž‘; 2, ‚žena‘).
A při práci s jinou entitou nechci vytvářet entity ‚sex‘, ale rovnou načíst text.Představoval bych si to nějak takto:
<?php
/**
* Entita reprezentujici osobu
*
* @property int $id
* @property string $sex m:hasOne(... sem nevím co dopsat ...)
* @property string $name
*/
class Person extends Entity
...
?>před 6 lety

- Tomáš Jablonický
- Člen | 122
Entity se mi zdají trochu nedomyšlené :-). Určitě by bylo od věci anotace jednotlivých sloupců psát aspoň ke geterům nebo opravdu mapovat jednotlivé Columm jako privátní proměnné (Doctrine2 to má celkem pěkně zmáklé).
před 6 lety
- Tharos
- Člen | 1042
@Šaman: No, mělo by to jít vcelku triviálně. :)
<?php
namespace Model\Entity;
/**
* @property int $id
* @property string $name
*/
class Author extends \LeanMapper\Entity
{
public function getSex()
{
return $this->row->referenced('sex')->name;
}
}
?>Pokusíme-li se poté o následující:
$authors = $authorRepository->findAll();
foreach ($authors as $author) {
write($author->name);
write($author->sex);
separate();
}Výpis bude například:
Kent Beck
muž
-----
Donald Knuth
muž
-----
Jane Davis
žena
-----
Elisabeth Schwarz
žena
-----
Thomas H. Cormen
muž
-----Připravil jsem Ti archiv, kde se si s tím můžeš kdyžtak hrát. Přes anotaci tohle zapsat nejde, ale řešení přes metodu je banální.
Jinak tak, jak to posílám, je to pohlaví pouze read only. Klidně dej
vědět, jak by sis představoval zápis a persistenci, a já podle toho tu
ukázku rozšířím. Chtěl bys vyloženě přiřazovat
$author->sex = 'male' a sám si hlídat si unikátnost hodnot
v číselníku?
Editoval Tharos (11. 6. 2013 10:43)
před 6 lety
- Tharos
- Člen | 1042
@jablon: Každou entitu, kterou zde uvádíme, lze přepsat do podoby bez jediné anotace. Jenom je s tím děsně psaní, takže doporučený způsob je použít anotace všude tam, kde to je možné.
V Lean Mapperu má entita jasně dané veřejné API (a zvenčí je
nenarušitelná) a @property (respektive
@property-read) anotace se v něm do veřejného API
započítávají. Tohle není myslím nic troufalého, takhle se k tomu, co je
veřejné API, staví už snad všechna nejpoužívanější IDE (která pak
napovídají).
Přepsat položky na třídní proměnné a pak psát anotace k nim (jak se to dělá v Doctrine 2) neplánuji, protože to je to samé v bledě modrém, jen dokonce mírně upovídanější.
před 6 lety
- hrach
- Člen | 1810
Kdyz na to tak koukam, inspiroval jses nazvy z notorm, referenced & referencing, ale bohuzel, to bylo to nejhorsi, cos z tohoi mohl vzit. Nema to zadnou logiku. Kniha ma autora. referencing mluvi o tom, jak je realne vazba v sql vytvorena, ale vubec nepopisuje vztah mezi entitami. Je sice jasne, ze tvuj mapper pracuje jen s dibi, na druhou abstrakce do entit je prave to, co me ma odstrihnout co nejvice od SQL a zavislosti na ulozeni dat.
před 6 lety
- Tharos
- Člen | 1042
V první řadě díky za názor.
Přiznám se, že Tvé výhrady jsem pochopil až po přečtení poslední věty (řekněme částečně – výtka k logičnosti referenced/referencing mi i nadále přijde lichá). Z té jsem totiž pochopil, že v jádru problému smýšlíme jinak. A to je dobře! To činí svět podobných knihoven pestrý a je z čeho vybírat. :)
hrach napsal(a):
abstrakce do entit je prave to, co me ma odstrihnout co nejvice od SQL
Situace se má tak, že já si za cíl odstřižení od SQL prostě nekladu. Pro mě nemají entity ten přínos, že vše je dokonale abstraktní a když budu potřebovat, zítra vyměním mapper.
Pro mě mají entity ten přínos, že představují nějaký zapouzdřený nenarušitelný celek s jasným API a že mám možnost umístit do nich (spolu s repositáři) business logiku, která by se mi v samotné databázi vyjadřovala nepohodlně (například že autor může být autorem maximálně pěti knih; někdo si může půjčit kolik chce knih, ale pouze od tří různých autorů…). Pokud v takovém zadání nemám entity (a repositáře), musím řešit, kam s touhle logikou. Nezřídka kdy se pak roztrousí všemožně po aplikaci (někdy přeteče až do šablon!), začne se opakovat… Samozřejmě jsou i jiné vzory, jak tohle řešit (třeba takový Table Module), ale prostě entity tohle řeší zdaleka nejelegantněji.
Následně pro mě mají entity ještě ten přínos, že skrze ně mohu data upravit a pomocí nějakého repositáře pak i persistovat (plus vytvořit a smazat).
To, že mě nějak odstíní od SQL nebo mi umožní jednoduše vyměnit mapper, má pro mě osobně význam o řád menší. V tomhle mi bohatě stačí, že pod pokličkou je DBAL, takže například přechod z MySQL na PostreSQL by byl snadno proveditelný.
Inspirován komentářem od Honzy Tvrdíka jsem v neveřejné větvi začal přepisovat Lean Mapper tak, aby byl plně kompatibilní s Data Mapper vzorem. Tuhle větev už jsem ale opustil, protože s postupujícím návrhem (k implementaci jsem se pořádně ani nedostal) bylo zjevné, jak ORM nakyne, a co hůř, o co kostrbatěji se v něm bude mapovat. Až se zdálo, že řada problémů pak nepůjde nějak snadno vyřešit vůbec.
Editoval Tharos (28. 1. 2014 16:34)
před 6 lety
- hrach
- Člen | 1810
Situace se má tak, že já si za cíl odstřižení od SQL prostě nekladu. Pro mě nemají entity ten přínos, že vše je dokonale abstraktní a když budu potřebovat, zítra vyměním mapper.
Prosim te, jeste jednou se zamysli, a udelej si klidne anketu. NIKDO bez precteni manualu nevi, jestli ma pouzit referenced, nebo referencing. Je to proste slozite. Metody hasMany, nebo belongsTo (hasOne) jsou naprosto vyrecne.
před 6 lety
- Tharos
- Člen | 1042
Proto taky ty příznaky m:hasMany a m:belongsTo(One|Many) v Lean Mapperu jsou (a taky m:hasOne).
Díky za názor. Neztotožňuji se s ním, ale beru ho na vědomí. Pokud se ozve víc lidí, že je tohle pro ně složité, budu nad tím přemýšlet. Myslím, že je v tomhle vlákně vidět, že se snažím uživatelům naslouchat a na vše reagovat. Prioritně pak řeším konkrétní dotazy, protože ty abstraktní bývá někdy problém zodpovědět („nemá to žádnou logiku“ – opravdu žádnou?; „to bylo to nejhorsi, cos z tohoi mohl vzit“ – proč?).
Bude skvělé, když své myšlenky naimplementuješ v Nextras\ORM. Zase bude větší výběr ORM a ti, kterým jedno přijde složité, budou snadno moci přejít k jinému.
před 6 lety
- Šaman
- Člen | 2275
@Tharos: Díky za vysvětlení. Měl jsem to
v anotaci, dokud jsem měl sex jako samostatnou entitu, která mi ale přijde
zbytečná. A protože často není požadavek na editaci těchto
číselníků, myslím, že je zbytečný i repozitář.
Metodu setSex($string) si sice dovedu představit, ale zajímalo by
mě, jestli to lze nějak efektivně (ten způsob s refeferenced jsem taky
neznal). Můžeš ji nastínit? Není potřeba dělat na to příklad, spíš mi
jde o to, jestli na to existuje podpora, nebo si mám sex_id
nastavit ručně.
A propo, tohle je vlastně práce s výčtem, jen je ten výčet zapsaný
v db místo v entitách.
// Jinak s tím referenced – taky se mi nelíbí, že je to
vlastně dotaz v entitě. Ale na druhou stranu bez tohoto bych potřeboval
právě i tu entitu a repozitáž Sex(Repository), tak přemýšlím, co
z toho je menší zlo..
//Edit2: Resp. zajímalo by mě, co bys doporučoval pro práci s takovýmto
výčtem. Petrovo ORM (před pár lety) doporučovalo používat výčet
konstant zapsaných přímo ve třídě entity.
Typicky budu chtít s takovými tabulkami dělat:
- načíst všechny kvůli vytvoření formuláře
- v entitě, která na tuto tabulku odkazuje budu chtít getter a setter,
s pomocí kterých budu s textem pracovat stejně, jako kdyby to bylo textově
zapsáno přímo v mateřské tabulce (oddělení do dvou tabulek je totiž
čistě záležitost relačních db a normálních forem, entita si skutečně
myslí, že má property
$sex = "žena")
//Edit3: Tohle nesouvisí s minulým textem. Zjistil jsem, že entity, ani repozitáře nedědí z Nette\Object. Chápu, že nechceš mít ORM závislý na Nette, na druhou stranu když už je závislý na Dibi, byl by to takový problém? Chtěl jsem v repozitáři načítat ještě svoje anotace, ale běžná Nette postup mi samozřejmě nefunguje.
Editoval Šaman (11. 6. 2013 14:34)